
McPherson Building Supply LLC was founded in Orlando in 2015. In 2022, the founder opened a second warehouse in Tampa under "McPherson Industrial Supply." In 2024, she sold the Orlando operation to a regional competitor. The buyer kept the name, changed the bank account, and brought in new management. The Tampa operation rebranded to "MPS Industrial" and moved to a new address.
Your system now has four records where there used to be one:
- McPherson Building Supply LLC, 123 Main St, Orlando — original shell, new ownership.
- McPherson Industrial Supply, 456 Commerce Dr, Tampa — opened 2022, renamed 2024.
- MPS Industrial, 789 Harbor Blvd, Tampa — same entity as above, different name and address.
- McPherson Building Supply LLC, 123 Main St, Orlando — same name and address as the original, but different EIN, different bank account, different contact person, different beneficial owner.
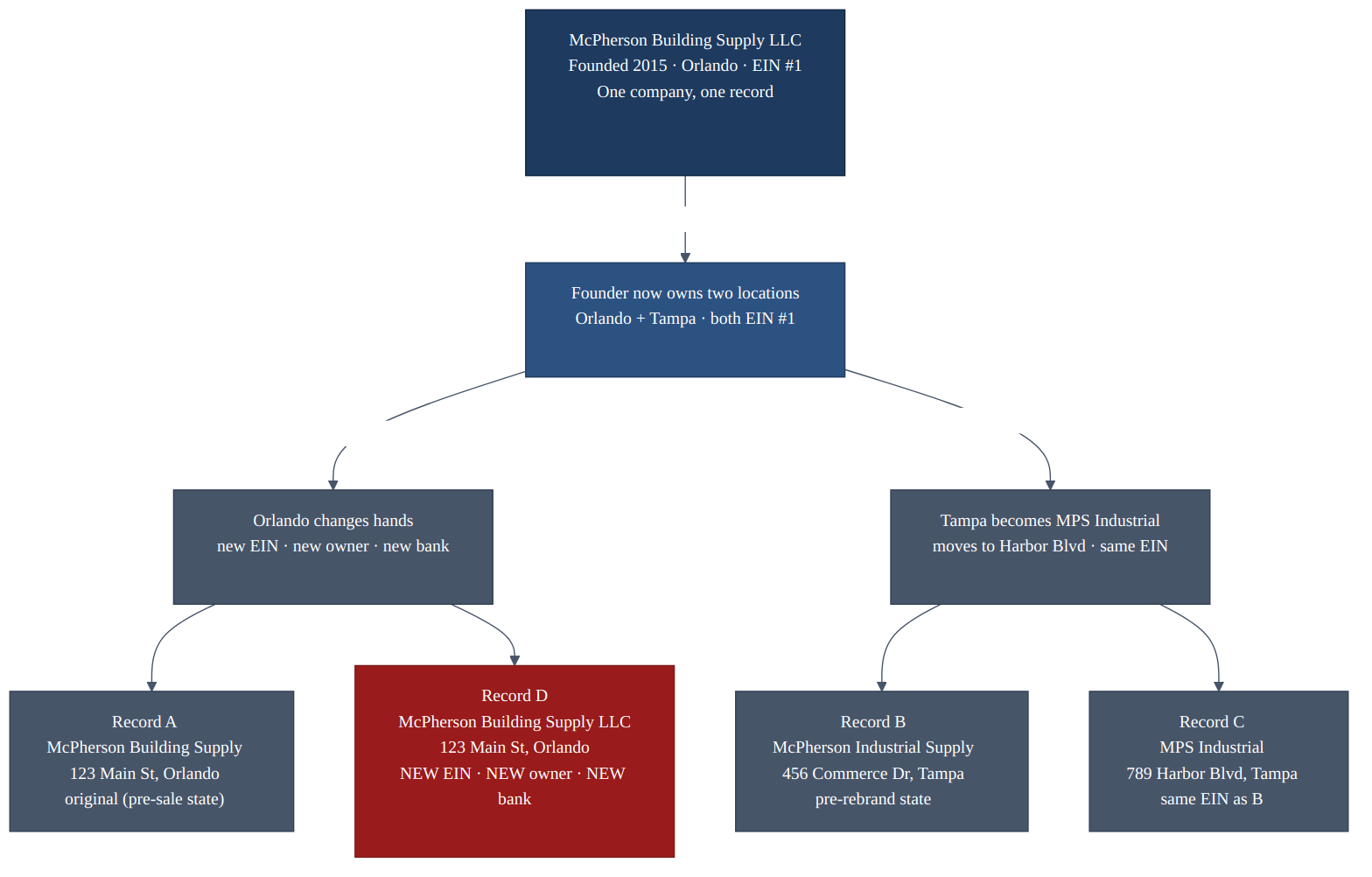
Which of these are the same entity? It depends on what you mean by "same." Same legal registration. Same beneficial owner. Same physical operation. Same payment relationship. The answer is different for each question, and different for each system that needs to ask it.
This is not a fuzzy matching problem. This is a temporal entity evolution problem. Every company that touches payments, fraud, compliance, lending, insurance, or supply chain hits this same wall.
Unit21 sees it as transaction monitoring. SentiLink sees it as synthetic identity. Alloy sees it as KYC/KYB. Sardine sees it as payment fraud. Castellum.AI sees it as sanctions screening. Healthcare calls it patient matching across hospital systems. AP teams call it vendor deduplication. Compliance calls it beneficial ownership tracing. The domain changes. The pattern doesn't.
The Fingerprint Problem
The traditional framing reduces entity resolution to string comparison. How close is "McPherson" to "MacPherson"? That is one signal among many, and by itself it answers almost nothing.
The real work is assembling a fingerprint from fragments scattered across structured and unstructured systems:
- Legal name and every variation — DBAs, trade names, former names, foreign-language filings.
- Addresses — registered, physical, mailing — and the full history of each.
- Tax ID / EIN.
- Bank accounts and routing numbers.
- Contact persons and the roles they play.
- Phone numbers and email domains.
- Website and broader web presence.
- Payment patterns — who they pay, who pays them, how much, how often.
- Document mentions — invoices, contracts, emails, regulatory filings.
- Relationships — parent companies, subsidiaries, shared beneficial owners.
Some of those signals are structured. Some are unstructured. Some are behavioral. A system that only matches on name and address is ignoring most of the available signal, which is why it always hits a ceiling and stays there.
The text-comparison piece is a solved problem. Levenshtein, Jaro-Winkler, TF-IDF, cosine similarity on character n-grams. They all exist, they all work, and they all handle the "is McPherson close enough to MacPherson" question. Google them. Fellegi-Sunter has been the classical probabilistic backbone of record linkage since the sixties, and it still shows up in production systems today.
None of that helps with the McPherson-Industrial-Supply-becomes-MPS-Industrial case. When the string changes completely, no string-matching algorithm saves you. You need the other signals. Same EIN. Same bank account. Same customers on the invoice list. Same contact person's cell phone. The name is the easiest signal to manipulate, which is why it is the least reliable one to rely on.
String matching is a component. It is not the solution.
From Matching to Graph
The more useful shift is from matching to graph.
Entity resolution is not the question "are these two records the same?" It is the question "how are these entities connected, and how have those connections changed over time?" That is a fundamentally different shape of problem, and it takes a different shape of system to answer it.
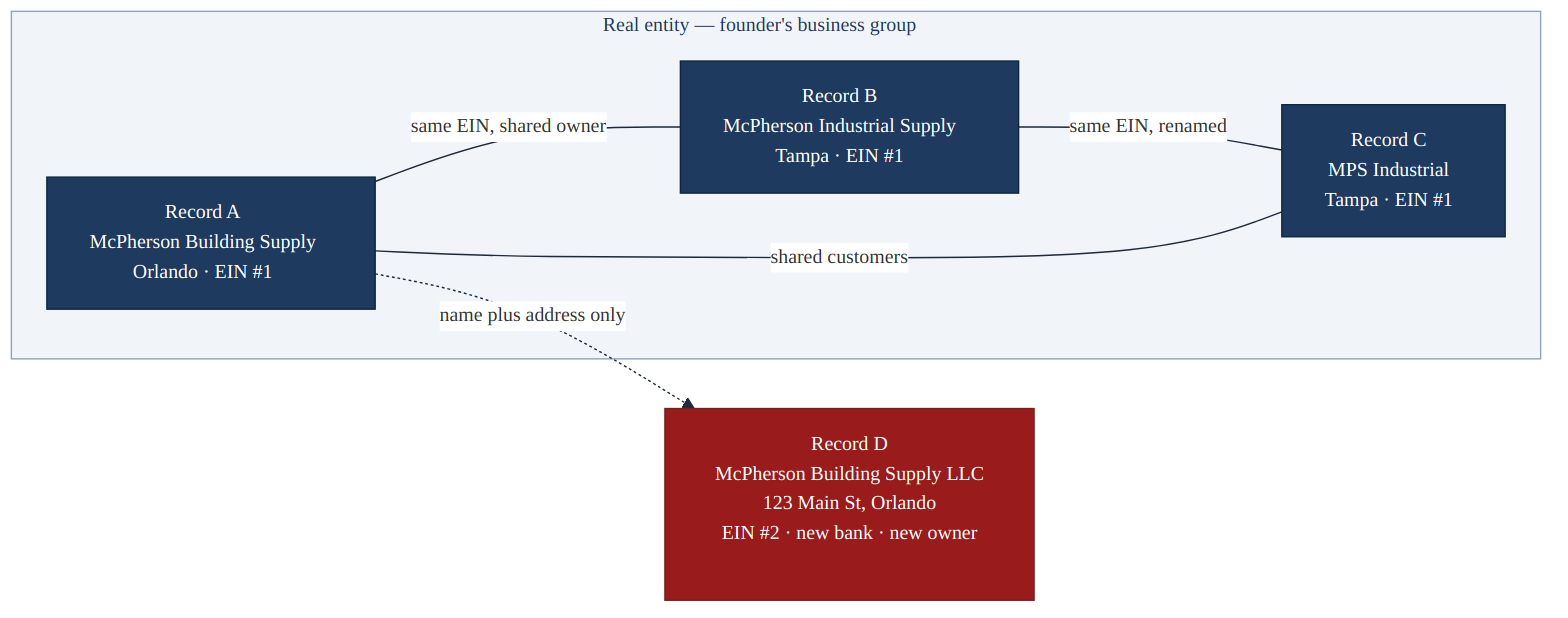
Go back to McPherson and add the signals beyond the name:
- Record A (McPherson Building Supply LLC, Orlando, original) and Record B (McPherson Industrial Supply, Tampa) share an EIN and a beneficial owner — the founder.
- Record B and Record C (MPS Industrial, Tampa) share an EIN. Same entity, renamed and relocated.
- Record A and Record D (McPherson Building Supply LLC, Orlando, post-sale) share a name and an address but differ on EIN, bank account, contact person, and beneficial owner.
- Records A, B, and C all have invoices from the same three customers going back to 2019.
- Record D has invoices from a completely new customer list.
String matching wants to collapse A and D together because the name and address line up exactly. It wants to split B and C because the name and address diverged. Both of those calls are wrong.
The graph tells the truth:
- A, B, and C form one cluster — the founder's business group — linked by EIN, beneficial owner, and a shared customer history.
- D is a separate entity that happens to occupy the same name and address shell. Different EIN, different bank, different customers.
Entities are nodes. Signals are weighted edges. The connected components of that graph are the real entities. Fraud detection does exactly this to find rings. Compliance does it to trace beneficial ownership through shell companies. Payments does it to collapse thousands of duplicate vendor records down to the handful of actual suppliers. Every one of those teams is walking the same graph with a different question.
BIAN's Party Reference Data Directory has had this structure as the banking industry reference model for a decade. Entities have a lifecycle. They change state. A record is a snapshot of a party at a point in time, not the party itself. Most production systems still treat the record as the party, and that mismatch is where most of the problems actually come from.
Detecting Change
Here is where most systems fail outright.
They treat entity resolution as a point-in-time snapshot. Match records today. Produce a score. Move on. The batch runs quarterly or annually, and in between runs the world keeps moving and the master data gets quietly wrong.
Entities evolve. A sample of what that actually looks like in the underlying signals:
- A bank account number changes on a vendor record. Could be routine — the vendor switched banks. Could be fraud — someone is redirecting payments. The record change looks identical in both cases.
- A contact person changes. Could be turnover. Could signal a quiet ownership change that the vendor has not disclosed.
- An address changes. Could be a move. Could be a post-acquisition consolidation.
- Payment cadence shifts. A vendor that always invoiced monthly starts invoicing weekly for smaller amounts. Possible structuring to stay under reporting thresholds.
- A new entity appears with the same phone number as an existing entity. Possible rebrand. Possible related company. Possible fraud.
- The EIN stays the same and the name and address change. Same legal entity, renamed and moved.
- The name and address stay the same and the EIN changes. Different company took over the shell.
In most organizations these changes are still detected manually. Someone in AP notices the bank account changed and places a phone call to verify. A compliance analyst catches a name discrepancy during a periodic review. A relationship manager notices payment patterns shifted during a quarterly business review.
The layers are collapsing. What used to require separate teams — data engineering to maintain the records, data science to build the matching models, compliance to review the changes, operations to act on them — is converging into systems that detect, classify, and route changes automatically.
A modern entity resolution system does not just match. It monitors. When a signal changes on an entity that has already been resolved:
- Detect the change. Delta monitoring between the current state and the previous state.
- Classify the change. Routine update, material change, or suspicious activity.
- Score the impact. Does the change move the entity's risk profile?
- Route the response. Auto-update for routine changes. Human review for material changes. Alert for suspicious patterns.
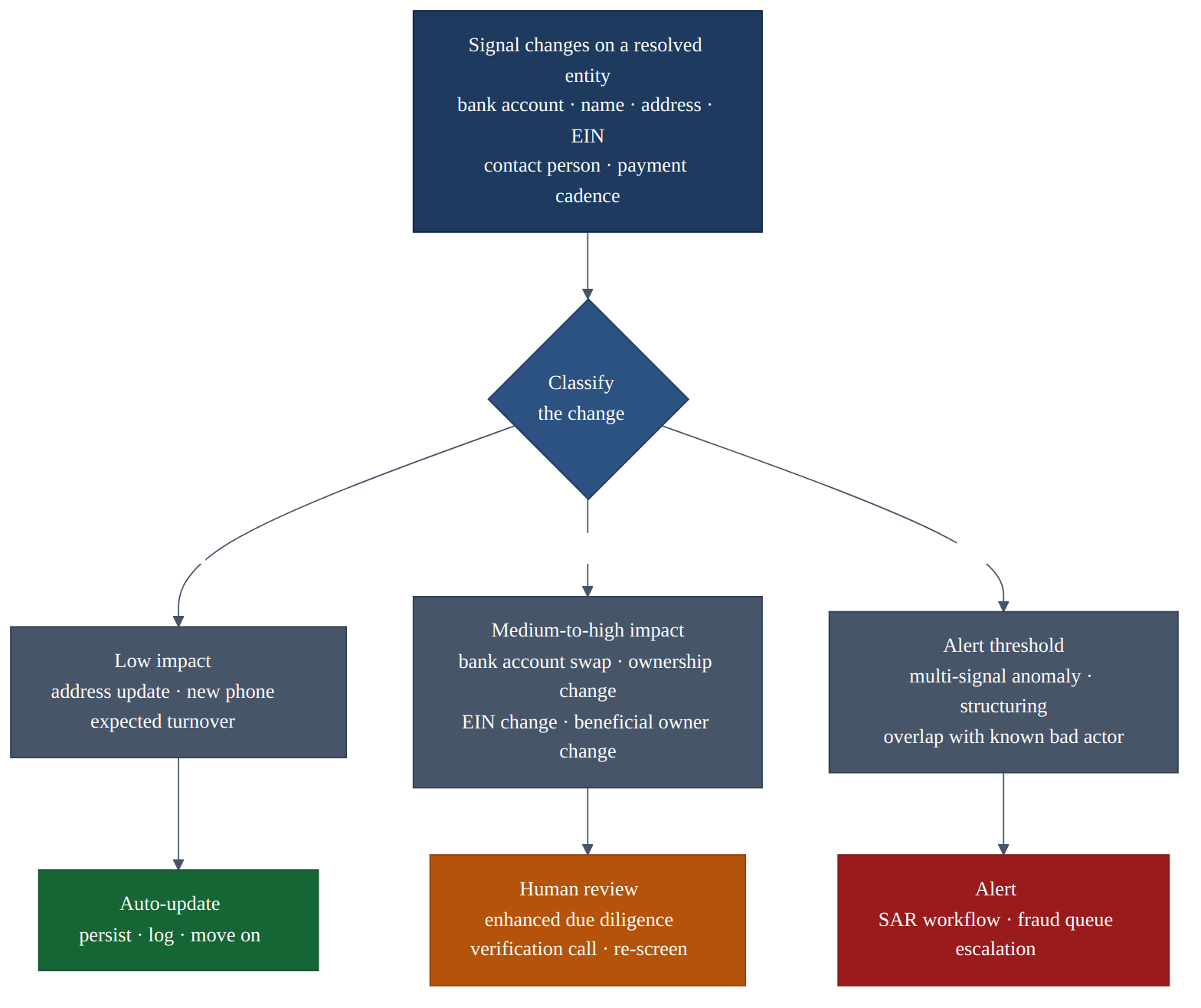
This is a confidence-gating pattern applied to change events instead of initial matches. The system that produced the match and the system that evaluates the change have to be independently operable. If the same model judges its own output and its own drift, you learn nothing new when it gets either one wrong.
What This Unlocks
Once you can detect and classify entity changes in something close to real time, you have stopped building a data-quality tool. You have built a source of business signal that did not exist before.
Compliance and risk. A vendor changes its bank account — automatic enhanced due diligence trigger. An entity matches a sanctions list after a name change — immediate escalation instead of a quarterly surprise. A beneficial ownership restructuring is detected — re-screen the whole group against watchlists. A payment pattern anomaly crosses a threshold — the SAR workflow kicks off on its own. OFAC screening is not a one-time check for this reason. Entities change, transliterations update, sanctions lists update, and a name that was clean yesterday can match a sanctioned entity today.
Fraud detection. Multiple new entities appear with shared signals — same address, same device fingerprint, same phone — and the graph surfaces a potential ring before the first loss lands. An entity's fingerprint suddenly overlaps with a known bad actor's — alert. Synthetic identity shows up as a cluster of individually plausible signals whose connections to the real world do not exist. Vendor payment redirection shows up as a bank-account change paired with a contact-person change in the same week — the classic business email compromise signature.
Operational efficiency. Vendor master deduplication after an M&A event. Instead of manually reconciling fifty thousand vendor records across two ERPs, the system builds the entity graph and flags duplicates, related entities, and conflicts in a single pass. Customer 360 — a complete view of every interaction across every system, even when the customer appears under different names or IDs in different ones. Supply chain consolidation — three "different" suppliers that turn out to be subsidiaries of the same parent, which turns into a single volume-discount negotiation instead of three.
Revenue and relationship intelligence. A customer's business is growing — new subsidiaries, new locations appearing in the graph — trigger proactive sales outreach. A vendor is consolidating or shrinking — supply-chain risk signal. Company A is connected to company B through shared ownership, and you already have a strong relationship with B — warm introduction. Industry clusters emerge from the connection patterns, and the map of a market starts to fall out of your own data.
The matching is the infrastructure. The graph is the intelligence. The change detection is the value. Most companies stop at matching, get the deduplication win, and congratulate themselves. The ones turning this into competitive advantage are the ones watching the graph over time and acting on what moves.
The Modern Stack
Brief outline here — the next post is the build.
Embeddings for candidate search. Pairwise comparison across a large entity set is O(n²) and collapses under its own weight past a few million records. Embed each entity into a vector space and use approximate nearest neighbor search — HNSW is the algorithm behind most vector indexes, including pgvector, under cosine, L2, or inner product — and the per-query comparison collapses to O(log n). Blocking used to be a separate pipeline stage. It does not have to be anymore.
Multiple signal types in a single index. Structured fields, unstructured text from emails and contracts, and behavioral data from payment history can all be embedded and searched in the same vector index. No separate pipeline per data type. One system, many signal sources, one candidate list per query.
A graph layer. Entities as nodes. Connections as weighted edges. The graph enables traversal queries that flat tables cannot answer — "show me every entity within two hops of this flagged vendor," "which entities share a bank account with this sanctioned target," "what is the beneficial-ownership tree for this holding company." That is where the intelligence lives.
A change-detection pipeline. Delta monitoring sitting on top of the graph. When an attribute moves, classify the change, score the impact, route the response. Same confidence-gating pattern as the initial match. Same independent-evaluator requirement.
An evaluation framework. Champion-challenger on the matching models. Segment-level metrics, not just aggregate accuracy. The aggregate lies. A matching model that is 95% accurate overall but 60% on the cases that actually matter to your business is not a 95% system. It is a 60% system, and nobody notices until it fails expensively.
In the next post, we build this. A working entity resolution engine that ingests messy business data, builds the fingerprint, resolves entities, constructs the relationship graph, and detects changes. Code on GitHub.
Close
Entity resolution is not a matching problem. It is a living system.
Businesses evolve. They merge, split, rebrand, relocate, change owners, change banks, change the people who sign the invoices. The system that identifies them has to evolve with them, or it will be quietly wrong about the state of the world in ways that you only discover when the loss lands or the regulator calls.
The companies getting this right — whether they sit in payments, fraud, compliance, lending, insurance, or supply chain — are not the ones with the best string-matching algorithm. They are the ones that built the whole stack. The fingerprint. The graph. The change detection. The verification layer around the model that catches the errors the model does not know it is making.
The domain changes. The pattern doesn't.
In the next post, we'll build one.
Have questions about this topic?
We love talking tech. Reach out and let's discuss how this applies to your business.