Follow-up to an earlier piece on how the enterprise decisioning stack is collapsing into a single AI-driven layer. If that is the direction things are heading, the next question is what makes that layer reliable in production.
Everyone is building AI models. Almost nobody is shipping the system that tells you whether the model was right. After working through the numbers on my own production pipeline, I'm convinced that gap is where the next wave of value sits.
The experiment that changed my mind
I run a KYB (know your business) verification pipeline in production. It classifies business entities against a closed set of labels, one of which is NONE for "no match found." To figure out how much of the accuracy was coming from the model and how much from the layers around it, I re-ran the pipeline through the same harness at three model precisions: FP16, INT8, and INT4. Same 542 labeled training examples, same 25 golden test cases, same production code path. No notebook experiment, no synthetic dataset.
Accuracy came back at 92% for all three precisions. The 8% error rate was not just roughly constant, it was identical, and when I broke out the confusion matrix every one of those errors was a false positive on NONE cases. Same failures at FP16 as at INT4. Whatever the variable was, it was not the model.
Confidence scores did not flag any of those failures. They could not have. The model was confident and wrong in the same way at full precision as at the smallest quantization level. The errors only surfaced against the labeled holdout, evaluated outside the model. That is the distinction I kept coming back to after the run: a confidence score is the model reporting on itself, and a confidence gate is a downstream system checking the output against something the model does not control. In this run the score never flagged a failure, and the gate caught them from the outside.
Then I did the thing most teams try first. I ran a LoRA fine-tune aimed at the NONE false-positive problem. Accuracy dropped to 12%. Not a marginal regression. The model picked up new wrong behavior and kept the old wrong behavior, and the cascade around the model still behaved exactly as it had in the baseline runs. What failed was the attempt to fix the model.
After that run I stopped tuning and started paying more attention to the system around the model.
The acquisitions point the same direction
While I was working through this, the external signal I kept noticing was what the top of the stack has been acquiring.
Anthropic bought Humanloop. Humanloop does not build models; it builds evaluation tooling, including prompt management, eval pipelines, and human-in-the-loop review. A frontier lab paid to own a company whose product is checking whether model output is correct.
CoreWeave bought Weights & Biases. W&B does not build chips; it builds experiment tracking and production monitoring for model runs. The largest specialized AI infrastructure provider paid to own a company whose product is measuring what those chips produced.
Two acquisitions are not a trend, but they are also not nothing. The training side and the infrastructure side made the same call at roughly the same time. Neither buyer is short on engineering talent, and neither was priced out of building internally. They acquired because the defensibility of these companies lives in assets that take years to assemble: labeled calibration sets, evaluation methodology, monitoring pipelines already ingesting real production traffic. Replicating that from scratch is slower than cutting a check.
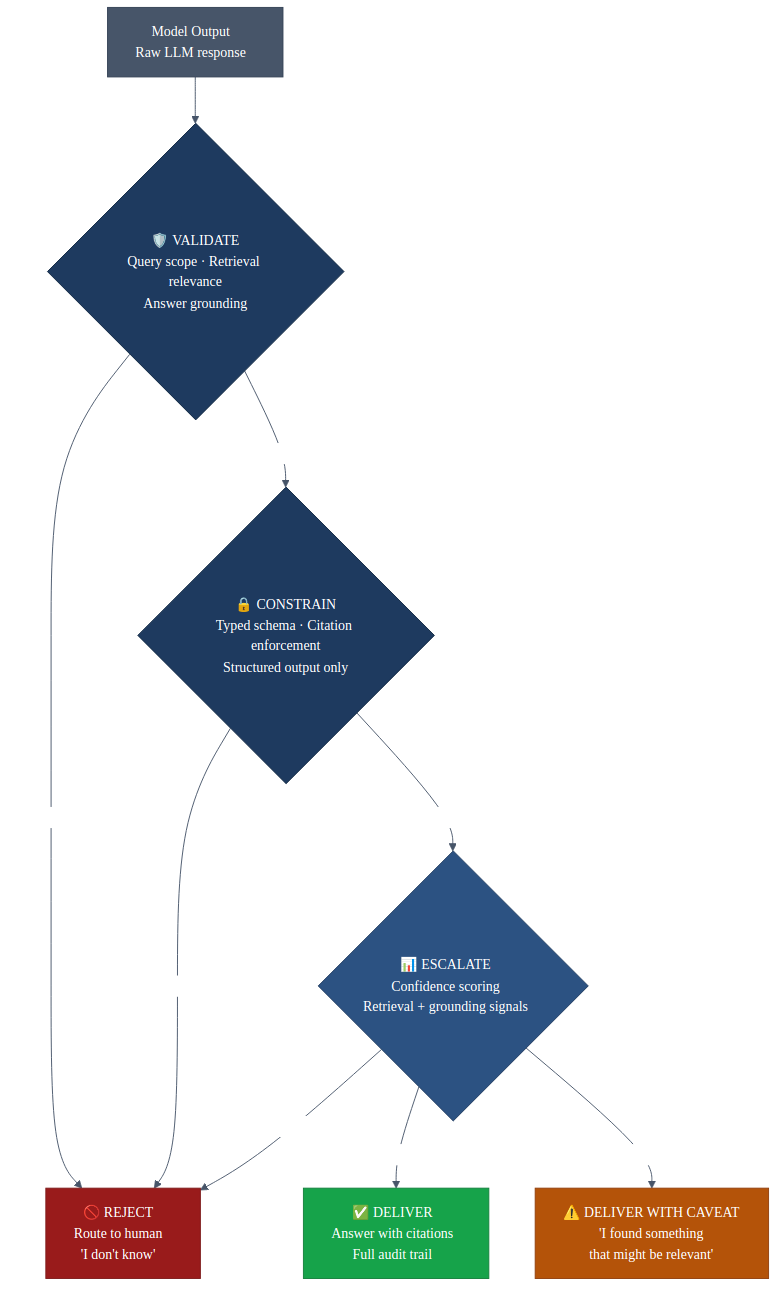
What the verification layer actually contains
When people hear "verification layer" they often reach for a confidence threshold and a smoke-test eval script. That is a small fraction of the work. The parts that actually matter, and the parts the acquired platforms are selling, look more like the following.
A labeled holdout set you do not train on. Mine is 25 hand-curated cases biased toward failure modes I have already seen in production. Coverage matters more than size.
Calibration of the confidence distribution. If the model reports 0.9 and it is right 60% of the time at that score, any threshold logic built on top of it is lying to you. Calibration can be corrected without retraining.
A cascade of checks, where each stage validates the output of the previous one before it moves forward: rules checks, second-source cross-references, structural validators. If the output does not survive a stage, the request escalates to a human queue rather than shipping. The quantization result above is only meaningful because the cascade catches errors the model does not know it is making.
Drift detection on inputs and outputs. The distribution you deployed against is not the distribution you will see next quarter, and you want to notice that before a customer does.
Feedback from outcomes back to thresholds. When an approved record gets disputed weeks later, that signal has to reach the threshold that approved it. Without that loop the gate is static, and static gates drift alongside the data they were calibrated against.
None of that infrastructure is the model, and none of it has to be rebuilt when you swap models or quantization levels. When I moved from FP16 to INT4, nothing in this list needed to change, which is part of why the accuracy number held.
Where this leaves "ship a better model" as a strategy
The capability gap between the major labs has been shrinking. Quantization means you can serve good-enough models at a fraction of the FP16 cost (the benchmark above is one of many data points pointing the same direction), and the infrastructure layer has already consolidated into a small set of hyperscalers.
The verification layer is not consolidated yet. Parts of it are being acquired at the top, but the portion that matters for any specific company — the labeled sets, the thresholds, the drift monitors calibrated to your own data and your own failure modes — has to be built where the work actually happens. The acquired platforms give you the floor.
If you are deploying AI into anything that matters, the fastest way to find out where your real problem is is probably to run the same pipeline at three precision levels and watch what changes. In my case nothing did, and that is why I now think the work is in the system around the model rather than in the model itself.