First post in a new series on making LLMs production-safe. The previous series covered building business process automation at scale — infrastructure, automation, where it breaks, and how to monitor it. This series picks up where that left off: what happens when you actually deploy these models and need them to be reliable.
The short version: Small open-weight LLMs — OLMo, Llama 3 8B, Mistral 7B — are fast, cheap, and you can run them on your own hardware. They're also wrong more often than the big models, and they're wrong with the same confidence. You don't fix that by waiting for a better model. You fix it with architecture. Two patterns: Defensive AI Architecture — treat every model output as untrusted until validated. Glass Box Architecture — make everything around the model transparent, typed, logged, and auditable. Together, they make unreliable models safe enough for production.
The Problem With Small Models
OLMo is interesting. Allen AI released a fully open 1B and 7B parameter family — open weights, open data, open training code. You can run it locally, fine-tune it, inspect exactly what it learned and why. For anyone building production systems on their own infrastructure, that's compelling. No API costs. No rate limits. No vendor lock-in. No data leaving your network.
There's one problem: small models are unreliable in ways that are hard to predict.
The big models (Claude, GPT-4) get it right 95% of the time on most tasks. A 7B model might hit 85%. That sounds close until you run it thousands of times a day. At 85% accuracy against 1,900 queries, you get 285 wrong answers daily. Every one propagates downstream. Your pipeline doesn't know the model was wrong. It just processes garbage as if it were gold.
So you want the small model — it's cheaper, faster, and keeps data on your infrastructure. You just can't trust it the way you trust the big one. Which means you need to build the trust into the system around it.
That's where the two patterns come in.
Defensive AI Architecture
The principle: treat every model output as untrusted. Don't hope it's right. Verify it is.
This isn't defensive programming in the traditional sense — checking for nulls and catching exceptions. It's a stance toward the model itself. The model is a supplier of unverified claims. The architecture around it is the verification system. No output reaches the user or the database without passing through at least one gate.
Every output gets one of four treatments:
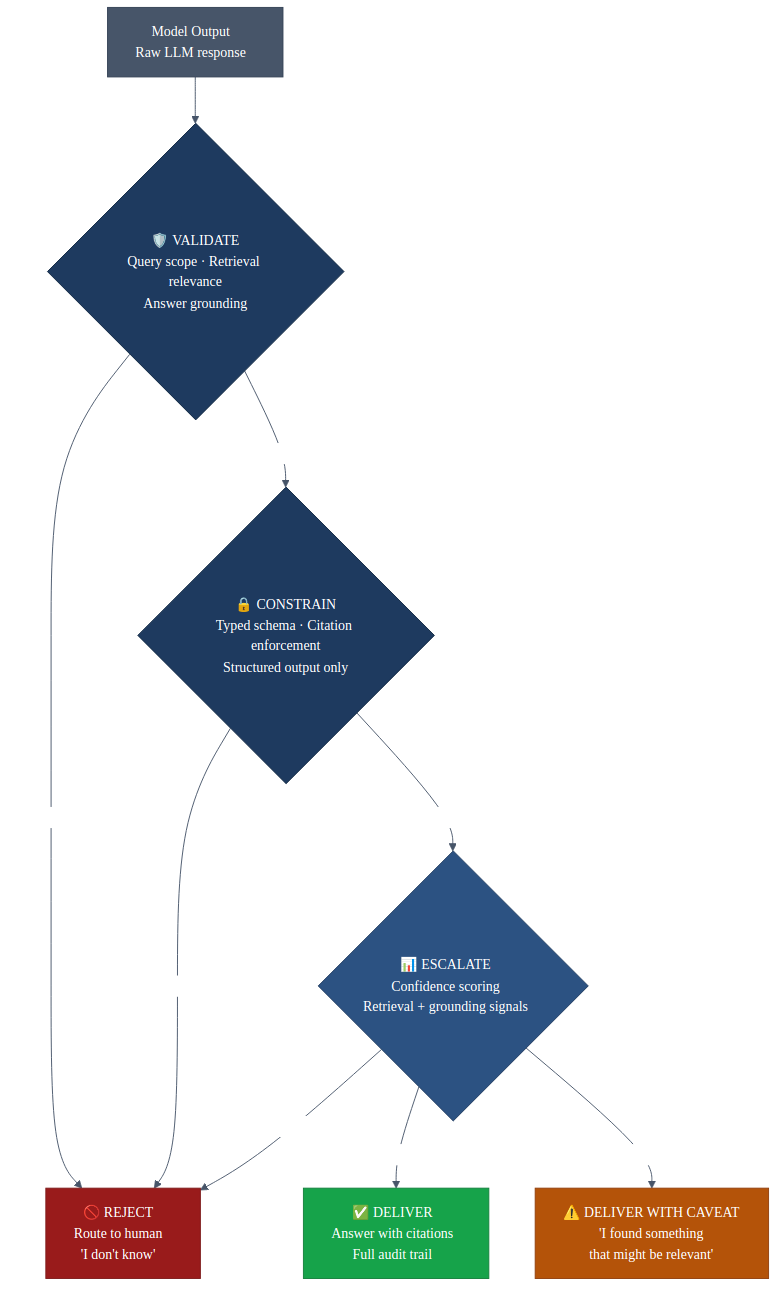
Validate
Check the output against reality before it goes anywhere. This applies at every stage of the pipeline:
- Query validation. Before the model even runs, check whether the question is in scope. A support agent asking "what's the weather" shouldn't burn a retrieval call and a model call. Scope detection is a cheap gate that saves expensive downstream work.
- Retrieval validation. You pulled chunks from a vector store. Cosine similarity above 0.8. But are they actually relevant? Embedding similarity measures semantic closeness, not answer-relevance. A chunk about "contract termination penalties" and a chunk about "contract renewal terms" are semantically close — both are about contracts. If the question is about early termination, only one helps. Check entity overlap, not just similarity scores.
- Answer grounding. The model generated a response. Does it actually come from the retrieved documents, or is it synthesizing from training data? Every claim in the answer should trace back to a source chunk. An answer that's 40% grounded is the model freestyling. Don't show it to the user.
Validate against reality, not against the model's confidence.
Constrain
Force outputs into known structure. Don't let the model freestyle.
"According to your records" isn't a citation. "FIS Master Agreement, Section 4.2, paragraph 3" is. "See our internal policy" isn't actionable. "HR Policy 2024-03, Section 7: Remote Work Eligibility" is. The output schema should force the model to attach a specific source to every claim — document name, section, chunk ID. If it can't cite it, it can't say it.
This applies beyond citations. Every stage of the pipeline should read and write to a typed schema. The model fills in fields or it doesn't. No freeform text flowing between stages. No unstructured dicts. Structured output is a constraint that prevents the model from doing things you haven't explicitly allowed.
The model proposes. The system constrains.
Escalate
When confidence is low, don't guess. Show the uncertainty.
Not all answers are equal, and the system should show the difference. A high-confidence answer — strong retrieval, high grounding, multiple supporting chunks — gets presented directly. A medium-confidence answer goes with a caveat: "I found something that might be relevant." A low-confidence answer is a soft handoff: the system is telling the user it needs help.
The user sees the system's confidence before they see the answer. This changes behavior. A legal team reviewing contract language trusts "here's the answer" differently than "I'm not confident in this — you may want to verify with counsel." A support agent checking product policy acts differently when the system says "this is the relevant section" versus "I found a partial match."
Don't present uncertain results with the same confidence as certain ones.
Reject
When validation fails, say no.
When the system can't retrieve relevant documents, or the retrieval is low-confidence, or the answer can't be grounded in sources — it says "I don't know" and routes to a human. Three outcomes: answer confidently, answer with a warning, or refuse.
An analyst asking about an internal contract deserves a correct answer or an honest "I'm not sure." They don't deserve a hallucinated clause number that sends them into a meeting with wrong information. A compliance team checking regulatory requirements can't work with made-up policy references. The cost of "I don't know" is a follow-up question. The cost of a confident wrong answer is a bad business decision.
"I don't know" is a valid, valuable output. Build it into the architecture as a first-class response, not an error state.
Glass Box Architecture
Defensive AI tells you what to do with model outputs. Glass Box tells you how to build the system around the model so every decision is visible, traceable, and auditable.
The principle: the model is a black box. Everything else is glass.
The model's internal reasoning is opaque — you can't see why it picked a particular answer. But every other decision in the pipeline should be transparent: what went in, what came out, why it was routed this way, and what evidence supports the final answer.
Four components:
Typed state. Every step in the pipeline reads and writes to a known schema. Every field is named and typed. When something goes wrong — and it will — you don't dig through logs trying to reconstruct what happened. You read the state object. It tells you exactly what each stage saw and what it decided.
Explicit routing. No implicit control flow. Every routing decision is a named function with typed inputs and outputs. The routing function doesn't hide inside a nested if/else buried in a 500-line file. It's standalone, readable in ten seconds, and its return type tells you everywhere it can go. When you need to understand why a query got routed to a human instead of answered, you read one function.
Decision logging. Every gate, every validation, every routing decision gets logged with its reasoning. Not application logs — structured decision records. Stage, action, result, reason, evidence, timestamp. When someone asks "why did the system give this answer," you pull the decision log and walk through it: query passed scope validation, 4 chunks retrieved with average similarity 0.82, 2 survived entity overlap, answer grounded at 87%, cited Section 4.2 of the source document.
Source-to-citation traceability. Every claim in the final answer traces back through a chain: answer sentence → grounding match → chunk ID → document name → section header → original source file. Nothing is hand-waved. Every link in the chain is a concrete reference a human can verify.
For regulated industries — financial services, healthcare, legal — this isn't optional. You need to explain not just what the system said, but why it said it and what evidence it used. But even outside regulated industries, Glass Box pays for itself the first time you debug a wrong answer. Logging tells you what happened. Glass Box tells you why it happened, with receipts.
Where OLMo Fits
Allen AI's OLMo is a good test case for both patterns because it pushes every boundary:
Size. The 1B variant runs on a single GPU with room to spare. Fast inference, low memory. But 1B parameters means less world knowledge, more hallucination, worse instruction following. A 1B model will cite the wrong section, invent document names, and generate plausible answers from training data instead of retrieved context — at a much higher rate than a 70B model. Defensive AI catches this.
Openness. Full access to training data and methodology means you can audit exactly what the model learned. You can fine-tune on your domain data without guessing what's in the base weights. For air-gapped environments or teams with strict data governance, this matters. Glass Box extends that openness beyond the model itself to the entire pipeline.
The tradeoff. You get control and cost savings. You give up raw capability. The engineering around the model has to be proportionally stronger. A 200B model might not need entity overlap checks on retrieval because it's better at ignoring irrelevant context. OLMo 1B will happily synthesize an answer from a chunk that's semantically close but topically wrong. The validation layer catches it regardless.
The architecture doesn't change based on model size. The thresholds do. With a stronger model, more queries produce high-confidence grounded answers. With a weaker model, more queries route to "I don't know" or human review. The system handles both because the layers are independent.
The Pattern
Two architectural patterns. One stance toward the model.
Defensive AI Architecture gives you four verbs for every model output:
- Validate — check it against reality. Does the query make sense? Do the retrieved chunks actually match? Does the answer trace back to sources?
- Constrain — force it into known structure. Typed schemas. Citation objects with document, section, chunk ID. No freeform text in the pipeline.
- Escalate — when confidence is low, show the uncertainty. Route to a human. Let the system say "I'm not sure" with the same clarity it says "here's the answer."
- Reject — when validation fails, say no. "I don't know" is a first-class response, not an error state.
Glass Box Architecture makes the system around the model transparent:
- Typed state so every stage reads and writes to a known schema.
- Explicit routing so every decision point is a named, readable function.
- Decision logging so every gate records what it saw, what it decided, and why.
- Source-to-citation traceability so every claim has a verifiable chain back to the original document.
The model is a black box. That's fine — you can't change that. But everything around it is glass. You can see every decision, trace every claim, and explain every answer. That's not a feature. That's the architecture.
Small models make both patterns more important, not less. OLMo at 1B needs every gate and every log entry. Claude at 200B+ could probably relax a few thresholds. But you build it once, and then you swap models in and out without restructuring anything.
The model is a component. The architecture is the product.
Get in touch if you're building something similar.