This is the third post in a series on building business process automation at scale. First: infrastructure. Second: automation. This time: where automation hits the wall — and why it's the same wall I've hit in every industry I've worked in.
Last week I walked through the KYB verification engine — eight automated signals per company, 1,900 companies a day. This week: why that's not enough.
Every morning I review a batch of freshly verified companies. About 80% of the results are solid. The other 20%? A GoDaddy parking page flagged as "website confirmed live." A vision model that picked a "Shop Now" button instead of a careers link. A DuckDuckGo result that matched "Pueblo Mechanical" to a plumbing outfit in Albuquerque. The agents aren't bad. They just aren't done.
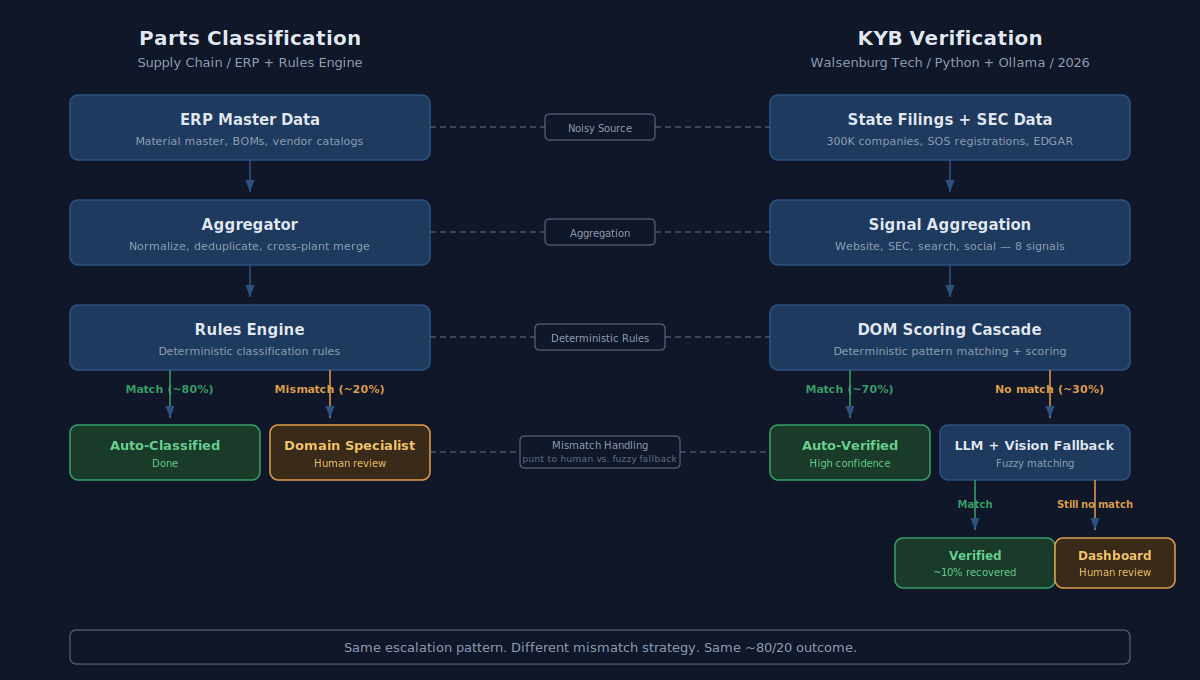
I've built this same escalation pattern before — a decade ago in global supply chain, with a completely different tech stack. The pattern is the same. The tools changed.
The Cascade
Career page discovery runs as a series of increasingly expensive fallbacks. Each layer exists because the one above it failed on real data.
- DOM Scoring — extract every link and button from the rendered page, score them for "careers-ness." Fast, deterministic, handles 70% of corporate sites.
- LLM Text Pick — when scoring finds nothing, send the element list to Llama 3 and ask it to pick. Handles the ambiguous cases — "Life at Acme Corp" is a careers link, not an about page.
- Vision Model Screenshot — when text fails, screenshot the page with numbered red badges on every navigable element, send it to a vision model. Catches icon-only navigation and image-based menus.
- Probe Fallback — try
/careers,/jobs,/join-usand see what responds.
The cascade is the architecture. The code below scores every link on a website to figure out which one is most likely the careers page — higher score means more likely. It rejects obvious non-matches (like "Shop Now"), gives top marks to exact matches (like "Careers"), and gives a bonus if the link is in the site's main navigation:
def _score_for_careers(el, *, base_domain=""):
text = el.get("text", "").strip().lower()
href = el.get("href", "").lower()
# Negative signals reject immediately
if _CAREERS_NEGATIVE_RE.search(text): # "shop now", "patient portal"
return 0.0
# Cross-domain links must point to a known ATS
if base_domain and href:
link_domain = _root_domain(href)
if link_domain != base_domain:
if not any(ats in link_domain for ats in _ATS_DOMAINS):
return 0.0
score = 0.0
if text in _CAREERS_EXACT: # "careers", "jobs" → 0.95
score = 0.95
for phrase in _CAREERS_PHRASES: # "join our team" → 0.80
if phrase in text:
score = max(score, 0.80)
break
if score > 0:
score *= _structural_modifier(el) # nav/header: 1.1x bonus
score *= _visibility_modifier(el) # invisible: 0.3x penalty
return min(score, 1.0)
When scoring comes up empty, the system sends a numbered list of every clickable element on the page to an AI model and asks "which one leads to the careers page?" The AI picks one or says "none of these":
# Each element: index | visible text | href | location (nav/header/footer/body)
# "0 | Life at Acme | /about/culture | nav"
# "1 | Shop Now | /store | header"
# "2 | Open Positions | /careers | footer"
payload = {
"model": "llama3",
"options": {"temperature": 0.0, "num_predict": 50},
}
When even that misses, the system takes a screenshot of the actual webpage, puts numbered red circles on every clickable element, and asks a vision AI to look at the picture and pick the right one:
_VISION_SYSTEM_PROMPT = (
"You are analyzing a screenshot of a webpage. "
"Red numbered badges have been overlaid on navigable elements. "
"Reply with ONLY the badge number of the best matching element, "
"or 'NONE' if no element matches the goal."
)
What Doesn't Work
The cascade handles most cases. The failures are at the edges — and they're the interesting ones, because the agents fail confidently.
The vision model picks random buttons. It doesn't say "I'm not sure." It picks "Shop Now" with full confidence. So when the AI picks a link, this code double-checks that the link actually has something to do with careers. If it doesn't mention careers, jobs, hiring, or anything related, the pick gets thrown out:
def _validate_llm_pick(el, goal):
"""Catches cases where the vision model picks random UI elements."""
if goal != "careers":
return True
for signal in (el.get("text", ""), el.get("href", ""), el.get("aria", "")):
if _LLM_CAREERS_SANITY_RE.search(signal): # "career|jobs|hiring|talent..."
return True
return False
A deterministic regex gate on a non-deterministic model output. That's the kind of code you end up writing.
Search results belong to the wrong company. DuckDuckGo doesn't know which "Pueblo Mechanical" you mean. This code strips out common business suffixes (Inc., LLC, Corp.) and checks whether the company name actually appears in the search result's website address or description. If it doesn't match, the result gets tossed:
def _search_matches_company(name, search_url, snippet):
norm = _SUFFIXES.sub("", name).strip().lower() # "Pueblo Mechanical, Inc." → "pueblo mechanical"
domain = urlparse(search_url).netloc.lower().replace("-", " ")
if norm in domain:
return True
if snippet and norm in snippet.lower():
return True
return False
HTTP 200 doesn't mean "real website." GoDaddy placeholders, squatters, "domain for sale" pages — all return a perfectly valid 200. This list of red-flag phrases catches fake websites — parked domains, "for sale" pages, placeholder sites that look alive but aren't real businesses. Every phrase in this list was added after I caught one in review:
_PARKED_PATTERNS = re.compile(
r"domain for sale|buy this domain|parked free|godaddy|sedo\.com|"
r"hugedomains|afternic|dan\.com|is for sale|this domain|"
r"parking page|under construction|coming soon",
re.IGNORECASE,
)
Rate limits kill the whole pass. DuckDuckGo rate-limits hard. Early versions would hit the wall mid-batch and just stop — half the companies left without search signals. Now there's a circuit breaker: three consecutive rate-limit errors and the search pass stops cleanly instead of persisting empty results.
I've Built This Before
A decade ago I was doing the same thing in global supply chain — different tools, same escalation pattern.
A large electronics manufacturer maintains a parts catalog across dozens of plants worldwide. Each plant keeps its master data in an ERP system — material records, bill of materials structures, vendor info, demand history. Massive, noisy, inconsistent across facilities. Same part under different material numbers at different plants. Vendor records incomplete. Lifecycle statuses stale. If that sounds like scraping 300,000 companies from state Secretary of State databases, it should.
The goal was fingerprinting every part — classifying it by commodity, sourcing strategy, lifecycle stage — so procurement could make decisions at scale. We built it as an escalation pipeline against ERP master data.
- Source layer — ERP master records. Material master, BOM structures, vendor catalogs, demand patterns. Authoritative in theory. Messy in practice.
- Aggregation layer — Normalize, deduplicate, merge across plants. Same job the KYB engine does when it pulls 300,000 companies from state filings and SEC data — take noisy source data and get it into a shape where rules can run against it.
- Rules engine — Deterministic business rules that classified parts automatically. Rule sets matched against material attributes, vendor history, and demand signals. For straightforward parts with clean data and established suppliers, the rules classified at high confidence. Same thing DOM scoring does — deterministic triage that handles the clear cases fast.
- Mismatch handling — Parts that couldn't be auto-classified generated a case, routed to the right commodity specialist. The case arrived pre-populated with everything the system already knew: ERP data, classification attempt, confidence score, similar parts that had been classified before. The specialist wasn't starting from scratch. They were reviewing an evidence package. That's exactly what the KYB dashboard does — eight pre-computed signals so the reviewer isn't doing manual research.
- The human layer — Commodity specialists made the call. They had context the rules couldn't encode: supplier relationships, upcoming engineering changes, market conditions, which vendors were about to lose capacity. No rule engine could capture that. No LLM can either.
The architecture is the same:
What's Actually Different
One thing. It cuts both ways.
Deterministic rules either match or they don't. When they're wrong, they're wrong the same way every time, and you fix them by adjusting the rule. The failure mode is silence — no match, route to a human. That's a safe failure.
LLM agents fail confidently. The vision model doesn't say "I'm not sure." It picks the wrong button and moves on. That looks like a correct result unless a human catches it. That's why _validate_llm_pick exists — a deterministic guard on a non-deterministic output.
The upside: the LLM handles ambiguity that deterministic rules never could. "Life at Acme Corp" is obviously a careers link to a human and to an LLM. To a rules engine, it's a miss. The 80% line is the same, but the composition is different. The agents catch nuanced cases the rules would've missed, while occasionally hallucinating on cases the rules would've handled cleanly.
The Weakest Link
Here's what nobody talks about when they say "AI can process thousands of records per day." It can. The KYB engine processes 1,900 companies a day. But speed doesn't fix accuracy — it amplifies whatever your accuracy already is.
A 5% false-positive rate sounds fine until you do the math. At 1,900 companies per day, that's 95 results that look correct but aren't. A parked domain marked as "website confirmed live." A search result matched to the wrong company. A careers page that's actually a store locator. They all land in the verified pile with the same confidence as the good results.
I saw the same thing in supply chain. The rules engine could fingerprint thousands of parts per day. But one bad classification doesn't just sit there — it propagates. A misclassified part gets the wrong commodity code, which pulls it into the wrong sourcing strategy, which routes it to the wrong supplier, which affects production schedules across plants. One bad data point at the top of the chain compounds through every downstream decision.
The value chain is only as strong as its weakest link. And the weakest link is always the same: the point where machine confidence exceeds machine accuracy. In supply chain it was a deterministic rule that matched the wrong material attribute. In the KYB engine it's a vision model that picks "Shop Now" with full confidence. Different mechanisms, same failure — the system says "I'm done" when it should say "I'm not sure."
That's why the handoff design matters more than the automation rate. The goal isn't processing more records faster. The goal is making sure the records that need a human actually get one — before they propagate.
Speed Without Accuracy
The agents can learn in a way that deterministic rules couldn't. Every parked domain I catch in review becomes a new pattern in _PARKED_PATTERNS. Every wrong button the vision model picks tightens _validate_llm_pick. The 80% line moves. Slowly, but it moves.
But the lesson from supply chain still holds: speed without accuracy is just making mistakes faster. The engineering isn't in the automation. It's in knowing where the automation stops and the human starts — and making sure that handoff is clean.
That's the practitioner's view. The agents work. At 80%. The engineering is in the other 20%.
But saying "80%" is an aggregate number — and aggregates hide where your system actually fails. In the next post, I'll show what happens when you break results down by segment using real ad tech data. The aggregate says "ship it." The segments say something different.
Get in touch if you're working on something similar.