Seventh post in a series on building business process automation at scale. Infrastructure. Automation. Where automation fails. Statistical validation. When models disagree. What to do about it. This time: a working system that puts all of it together.
The short version: A single fraud model gives you a number. It doesn't tell you why it's suspicious, or what to do when it's not sure. Sentinel is a fraud detection system built in three layers — rules that catch what's obvious, models that catch what's subtle, and a routing layer that sends the uncertain cases to a human instead of guessing. The same triage pattern from the last six posts, applied to money.
The Problem With a Single Score
Most fraud detection tutorials end the same way. Train a model. Get a score. Pick a threshold. Everything above 0.7 is fraud, everything below is fine.
That works in a Jupyter notebook. It falls apart in production.
Here's why: a model gives you a number between 0 and 1. It doesn't tell you why it flagged the transaction. A $12,000 purchase from Nigeria at 3am? The model says 0.85. A $200 grocery purchase with a slightly unusual card pattern? Also 0.85. Same score, completely different situations. The first one, a rules check would have caught in milliseconds without a model at all. The second one is exactly where you need the model — it spotted something a rule couldn't.
When you collapse everything into a single score, you lose the ability to explain your decisions. And in fraud, explanations matter. The compliance team wants to know why a transaction was blocked. The customer wants to know why their card was declined. "The model said 0.85" isn't an answer anyone can act on.
Three Layers, Three Jobs
Sentinel splits detection into three independent layers. Each one has a specific job, and they don't always agree — which is the whole point.
Layer 1: The Rules Engine
Five rules. Each one catches a specific pattern that doesn't need machine learning to identify. Each rule has a weight, and the weights add up to a rules score between 0 and 1. It's deterministic, it's fast, and you can explain exactly why it fired.
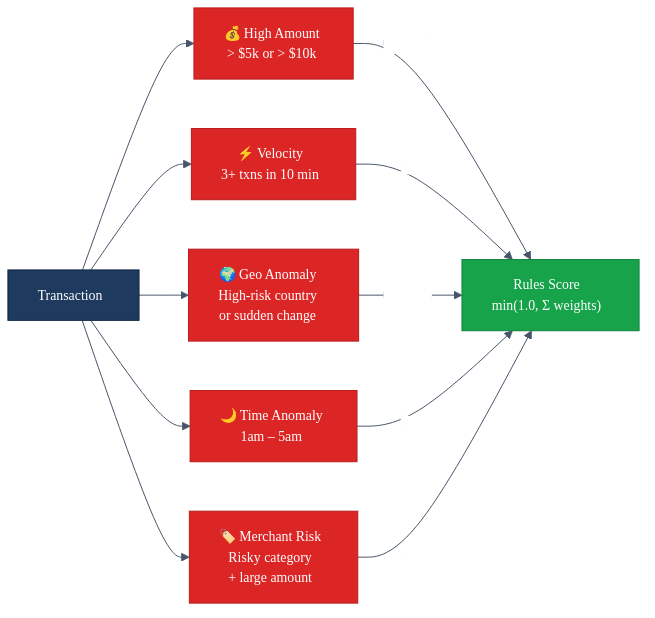
Rules are good at catching known patterns. The $15,000 electronics purchase from a country the cardholder has never visited? The rules engine flags that instantly. No training data required. No model drift to worry about.
Rules are bad at catching subtle patterns. The slightly unusual purchase that doesn't break any single rule but looks wrong when you consider everything together? That's what the model is for.
Layer 2: The ML Models
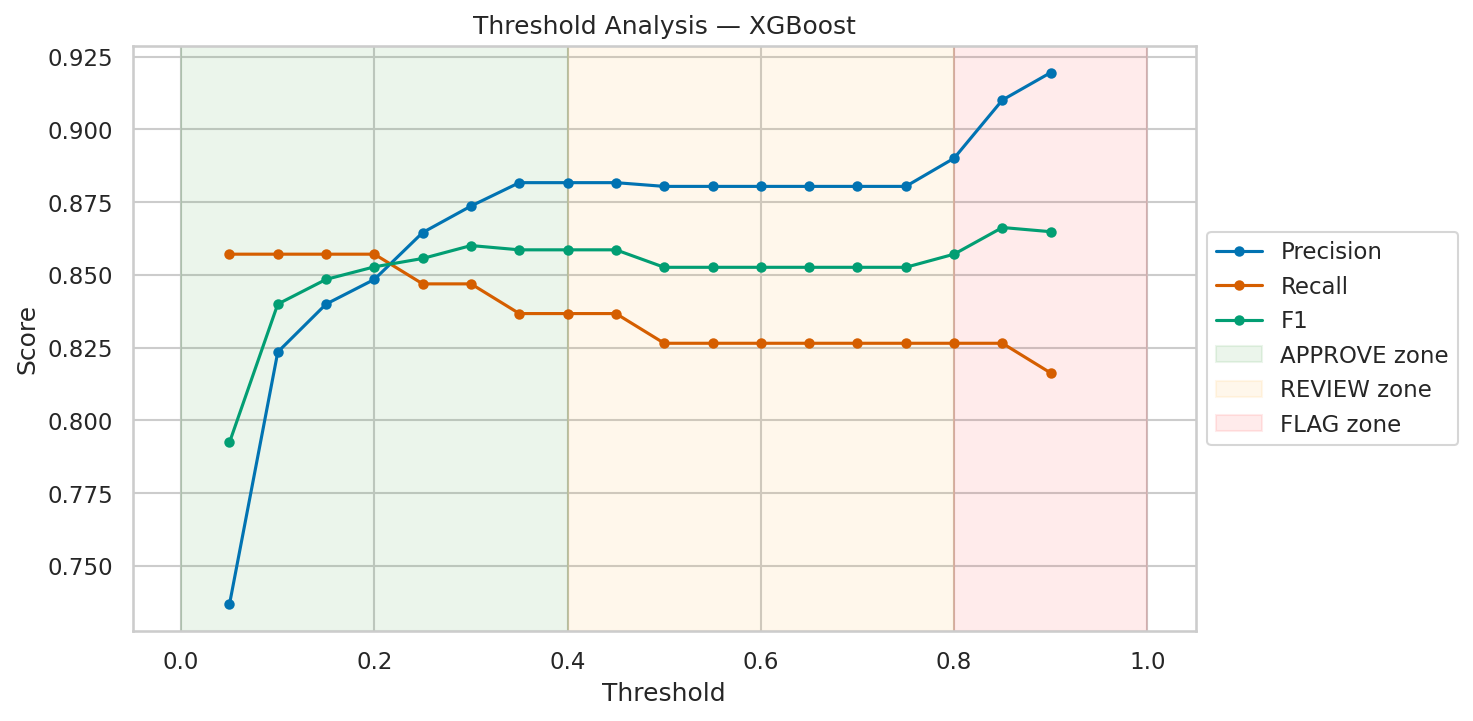
We trained four models on real fraud data — 284,000 credit card transactions with a 0.17% fraud rate. That extreme imbalance is the whole challenge. For every fraudulent transaction, there are 577 legitimate ones.
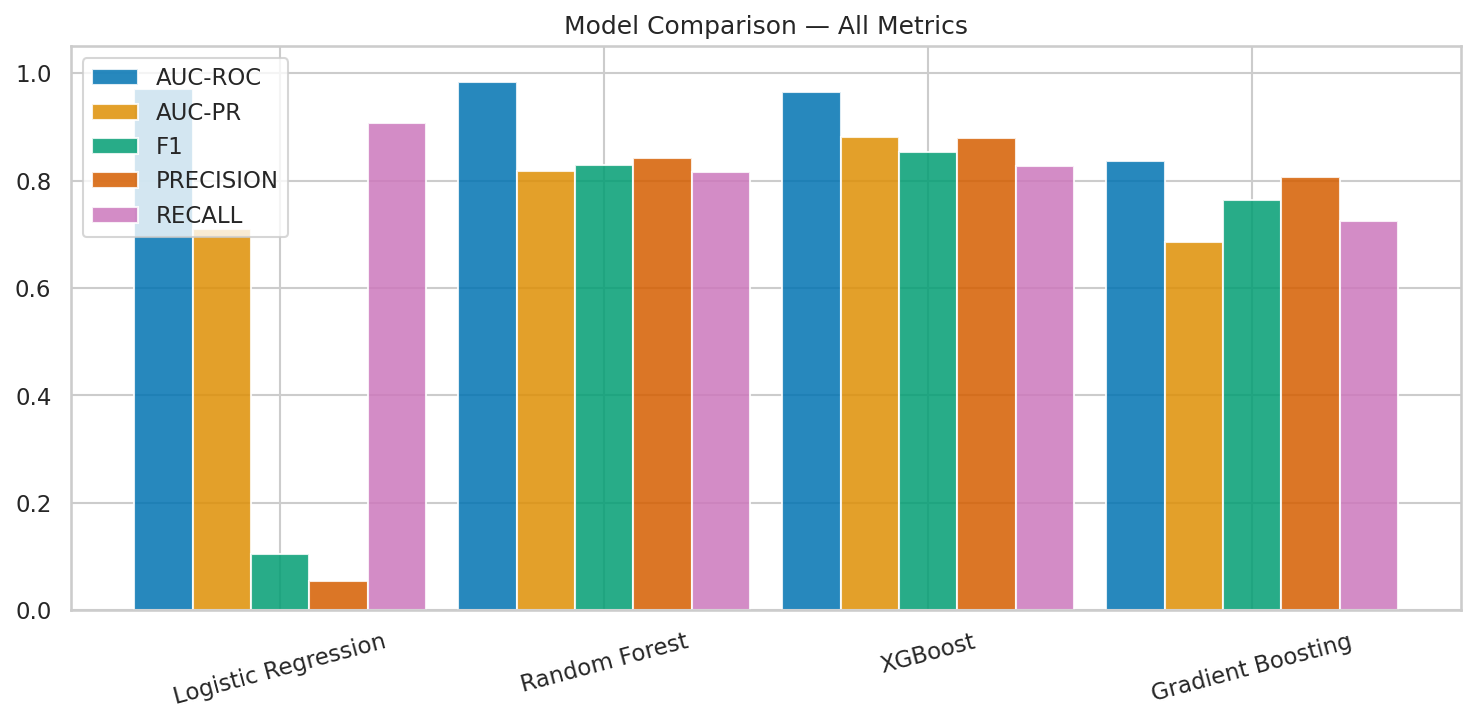
XGBoost came out on top — 88% precision, 83% recall. Random Forest was close behind. Gradient Boosting missed more fraud and took 17 minutes to train. But the logistic regression result is the one worth staring at. 91% recall sounds great — it catches 91 out of 100 fraudulent transactions. But 6% precision means that for every real fraud it catches, it also flags roughly 16 legitimate transactions. At scale, that's thousands of false alarms per day. Your fraud team drowns. Your customers get angry. The "best recall" model is actually the worst option for production.
This is the precision-recall tradeoff, and it's a business decision, not a math one. How many false alarms can your team handle? How much fraud can you afford to miss? There's no universally correct answer. XGBoost at 88% precision and 83% recall was our best balance, so it runs as the champion model.
But we don't throw away the others. All four models live in BentoML's model store. We can swap the champion at runtime — no restart, no redeployment. If XGBoost starts underperforming, we promote Random Forest with a single API call.
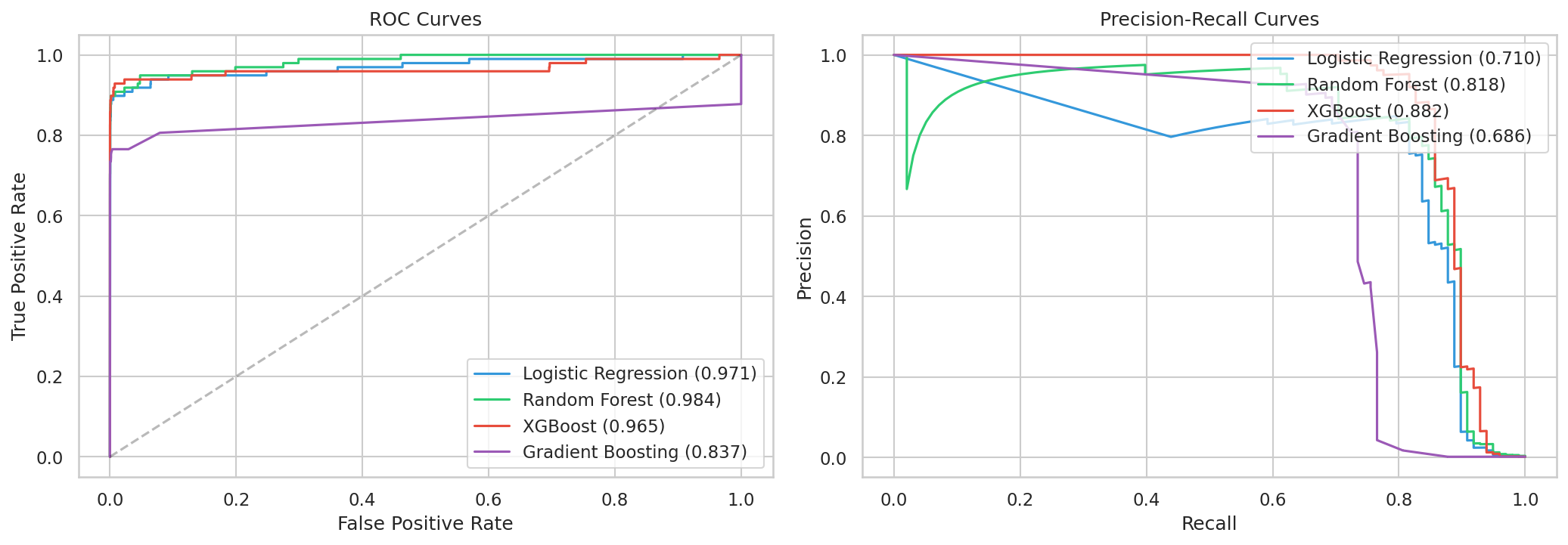
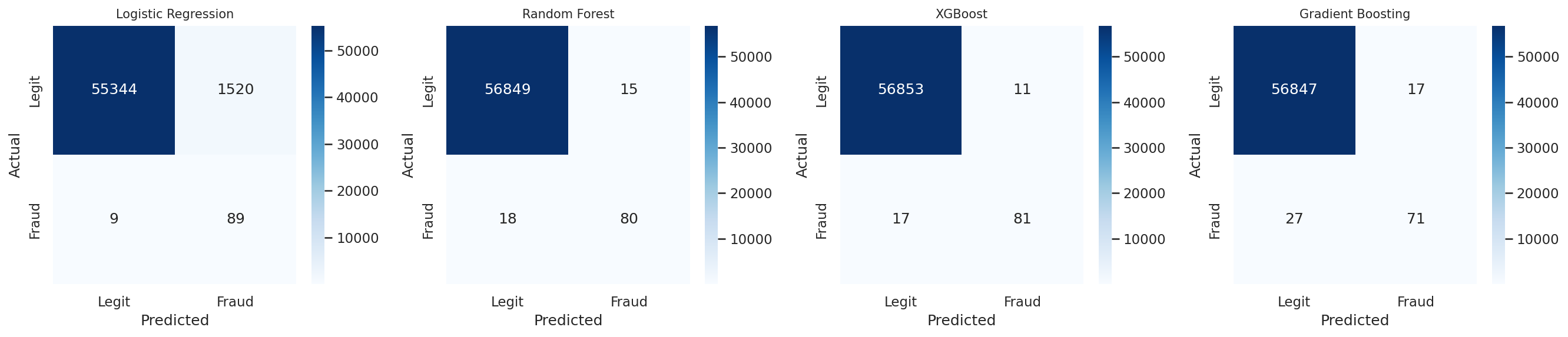
Layer 3: The Escalation Router
This is the triage layer from the previous post, built into the system.
The router looks at both the ML score and the rules verdict, then makes one of three decisions:
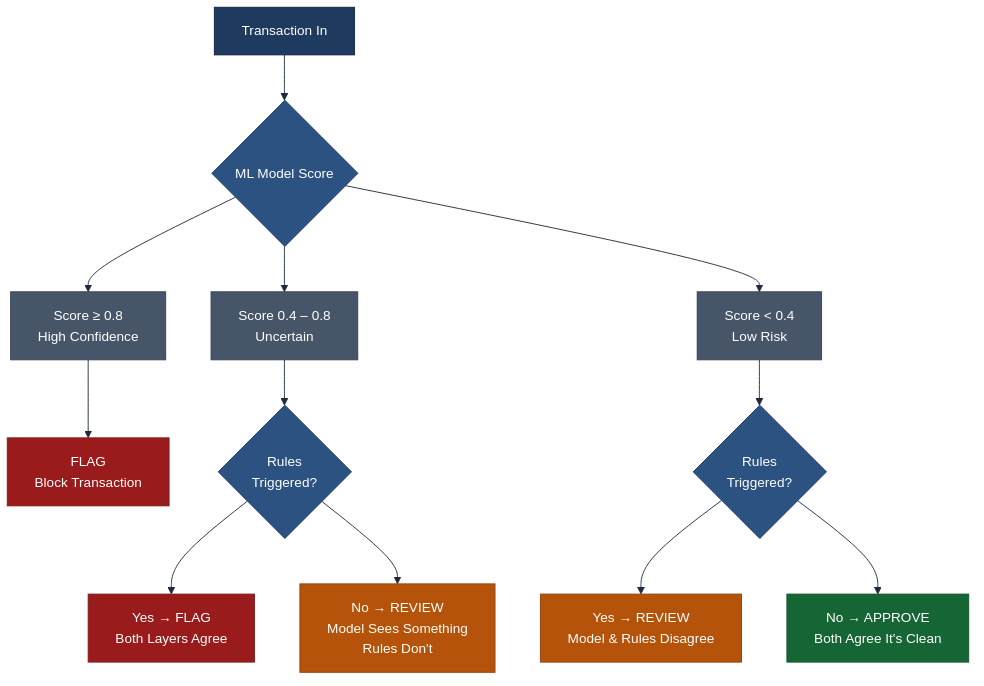
The middle row is the one that matters most. When the model is uncertain and the rules don't have an opinion, the system doesn't guess. It routes to a human review queue. That's the "I don't know" answer that most systems are afraid to give.
In fraud, confidently wrong is worse than honestly uncertain. A false approval costs you the transaction amount. A false block costs you the customer. "I'm not sure, please look at this" costs you a few minutes of an analyst's time. That's the cheapest mistake.
Watching for Drift
A model trained today won't work forever. Fraud patterns change. Card usage patterns shift. What looked normal six months ago might look different now — not because fraud changed, but because the world did.
Sentinel monitors this with a simple approach: track the distribution of scores over time. The first thousand transactions establish a baseline — what "normal" scoring looks like. Every transaction after that gets compared against the baseline using a metric called PSI (Population Stability Index).
If the scores start shifting — more transactions landing in unusual ranges, the average score creeping up or down — the PSI climbs. When it crosses 0.2, the system flags a drift alert. That doesn't mean the model is wrong. It means the model is seeing something different from what it was trained on, and someone should investigate.
Drift detection isn't about catching fraud. It's about catching the moment your fraud-catching tool stops working. The meta-problem. And it uses the same pattern as everything else in the system: measure, compare, flag when uncertain.
How It All Fits Together
The three detection layers are the what. The tooling underneath is the how — and picking the right tools is what makes the difference between a demo and a production system.
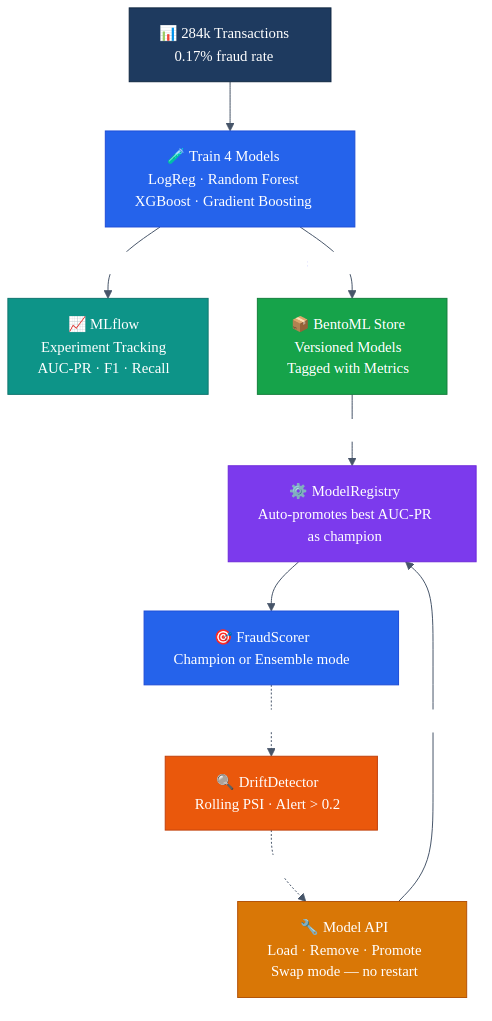
MLflow handles experiment tracking. Every training run logs its parameters, metrics (AUC-PR, AUC-ROC, F1, precision, recall), and artifacts to a central server. When you've trained four models with different hyperparameters across multiple iterations, you need a way to answer "which run produced the best XGBoost?" without digging through notebooks. MLflow is that answer — it's the lab notebook for the whole training pipeline.
BentoML is the model store. Once a model is trained and validated, it gets saved as a versioned artifact tagged with its framework, training metrics, and dataset. The key thing BentoML gives you that a bare pickle file doesn't: a standard interface. Every model — whether it's sklearn, XGBoost, or something else — gets loaded and called the same way. That's what makes hot-swapping possible. The API doesn't care which model is behind the scoring call.
The ModelRegistry sits between the store and the scoring pipeline. On startup, it loads every model from BentoML's store and automatically promotes the one with the best AUC-PR as the champion. In champion mode, only that model scores transactions. In ensemble mode, all four score and the results are averaged. The registry is thread-safe and lives in memory — no database round-trips on the scoring path.
The DriftDetector closes the loop. It tracks every score the system produces using a rolling window, compares the current distribution against the baseline using PSI, and flags when things shift. That alert feeds back to the management API, where an operator can investigate, retrain, or swap models — all without restarting the service.
The whole pipeline — train, track, store, serve, manage — runs in Docker Compose: PostgreSQL for transaction persistence, the Sentinel API (FastAPI + BentoML store), MLflow for experiment tracking, and a Streamlit dashboard for monitoring. One docker compose up and the entire system is running.
What This Architecture Gets You
Three things that a single-model approach can't provide.
Explainability. When a transaction gets flagged, you can say exactly why. "The rules engine triggered on high amount and geo anomaly. The ML model scored it at 0.73. The escalation router sent it to review because the model was uncertain." That's an explanation a compliance officer can work with.
Graceful degradation. If the model store is empty — no models trained yet, BentoML down, whatever — the rules engine still works. If the rules engine has a blind spot, the model covers it. Neither layer is a single point of failure. They're independent signals that combine into a stronger one.
Operational control. Four models in the store. Swap the champion based on this week's performance metrics. Switch to ensemble mode (average all four) during high-risk periods. Remove a model that's drifting. Add a new one trained on fresh data. All through API calls, all without touching the code.
The full source is on GitHub: avatar296/sentinel.
The Pattern Underneath
Six posts ago, I started with infrastructure. Then automation. Then the limits of automation. Then validation. Then model disagreement. Then triage.
Sentinel is all of those things in one system.
The rules engine is automation — fast, deterministic, limited to known patterns. The ML models are prediction — powerful, opaque, trained on general data. The escalation router is the triage layer — the part that knows when to trust the automation, when to trust the model, and when to ask for help.
The competitive advantage isn't in any single layer. It's in knowing where each layer's lane ends and the next one begins. That's not something you buy off a shelf. It's something you build by running the system and watching where it breaks.
The fraud domain is different from business verification and ad tech, but the architecture is the same. Rules for what's obvious. Models for what's subtle. Humans for what's uncertain. Monitoring for when the whole thing starts to drift.
That pattern works everywhere. The details change. The structure doesn't.
Have questions about this topic?
We love talking tech. Reach out and let's discuss how this applies to your business.