Eleventh post in a series on building business process automation at scale. Infrastructure. Automation. Where automation fails. Statistical validation. Predictive models. When models disagree. A working system. Framework vs. architecture. MCP server. Making small LLMs safe. This time: what happens when you quantize the model and measure what actually changes.
The short version: Most teams serve LLMs at FP16 because they're afraid quantization will degrade quality. I tested that assumption on a real production verification pipeline — not a synthetic benchmark, not a notebook experiment. Same model, same test set, three precision levels. The result: zero accuracy loss, 5.6x faster inference, 6x lower cost at INT4. The quality fear is unfounded for constrained classification tasks. Here's the data.
Why This Matters
GPU inference cost is the single biggest variable expense for any company serving LLMs to users. If your model is doing structured classification — entity extraction, document categorization, compliance routing, element picking — and you're paying FP16 prices, you're probably overpaying by an order of magnitude. The question is whether you can prove it before you ship it.
That's what this benchmark does. Not "quantization works in theory." Quantization works on this pipeline, on this task, with this data. Measured, not assumed.
The System
Blueprint's KYB (Know Your Business) verification engine is a 4-layer agentic cascade that verifies business entities. I've written about the full architecture and the automation layer in previous posts. The piece that matters here is the LLM classification layer.
Given a list of DOM elements scraped from a company's website, the model picks the element most likely to lead to the target information — a careers page, a contact page — or says NONE if nothing matches. Structured input, bounded output space, deterministic evaluation criteria. It's a constrained classification task, and that distinction matters for interpreting the results.
The model runs locally via Ollama. No API calls, no rate limits, no data leaving the network. That's by design — the sovereign infrastructure post explains why.
The Experiment
Three quantization levels of the same model:
- FP16 —
llama3:8b-instruct-fp16. Full 16-bit floating point. The default that most teams deploy without questioning. - Q8_0 —
llama3:8b-instruct-q8_0. 8-bit integer quantization. Half the memory footprint. - Q4_0 —
llama3:8b. 4-bit integer quantization. A third of the original memory.
Same golden test set: 25 real KYB verification queries across two task types (careers and contact page discovery). Same evaluation: exact match against labeled correct answers. Same hardware.
Metrics tracked: accuracy, precision/recall per task type, latency (p50 and p95), peak memory footprint, tokens per second, and estimated cost per 1,000 queries mapped to A10G cloud pricing.
This isn't a separate notebook experiment. The benchmark harness is integrated into the existing pipeline — it runs the same code path the production system uses, just with instrumented timing and a fixed test set.
The Results
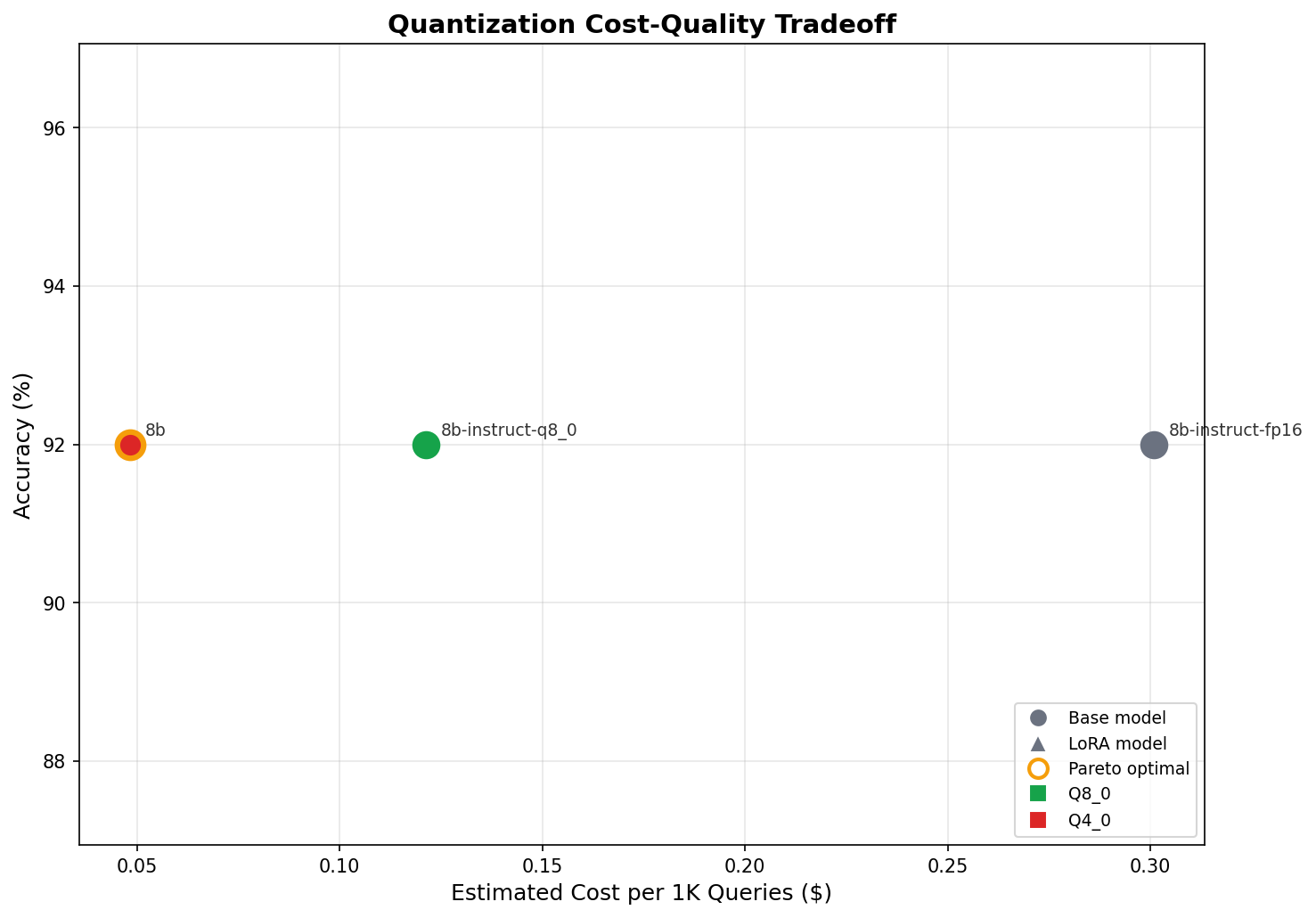
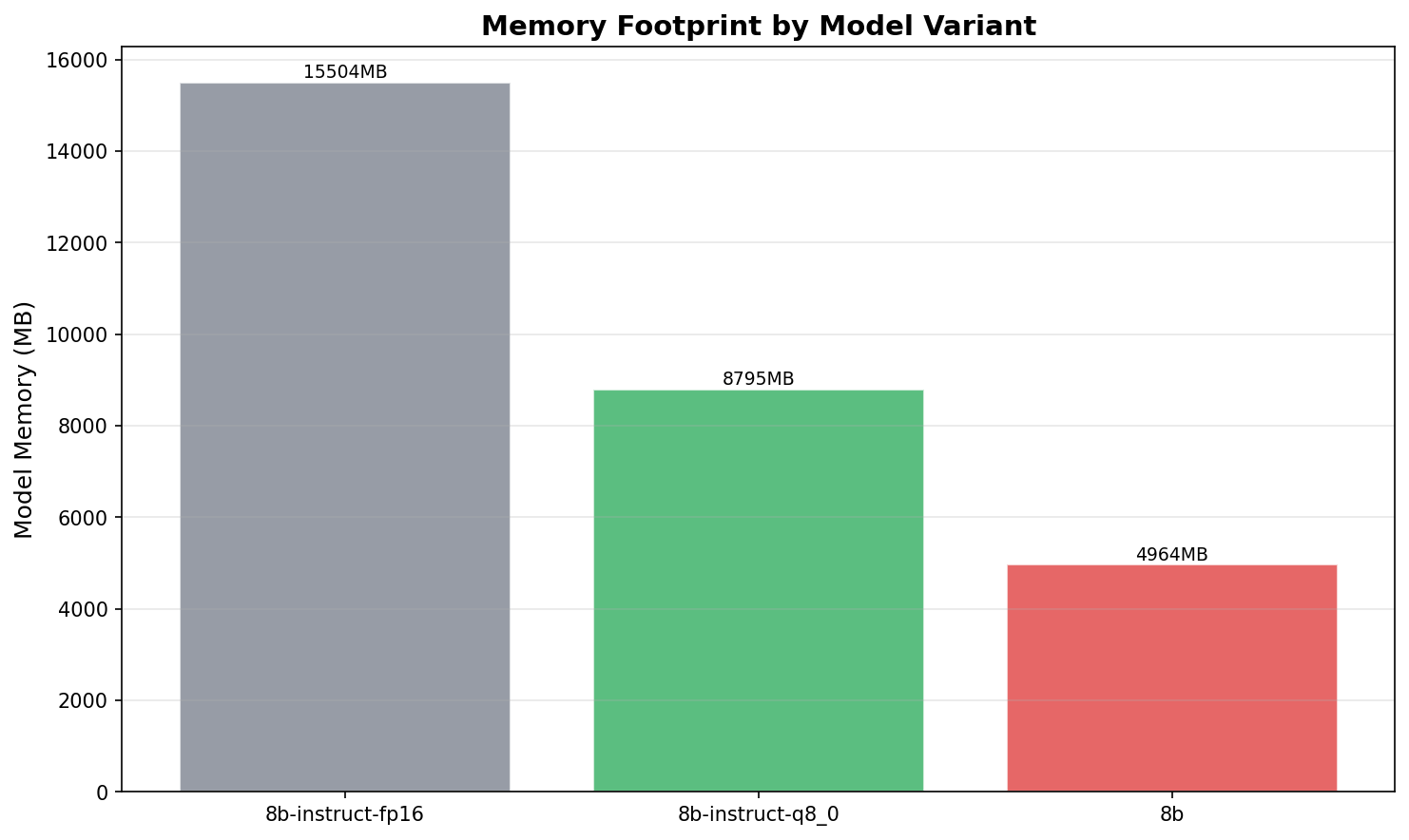
| Variant | Quant | Accuracy | P50 (ms) | P95 (ms) | Memory | Tok/s | Cost/1K | Pareto |
|---|---|---|---|---|---|---|---|---|
| llama3:8b-instruct-fp16 | F16 | 92.0% | 1,211 | 1,511 | 15.5 GB | 1.5 | $0.30 | |
| llama3:8b-instruct-q8_0 | Q8_0 | 92.0% | 504 | 657 | 8.8 GB | 3.7 | $0.12 | |
| llama3:8b | Q4_0 | 92.0% | 216 | 254 | 5.0 GB | 9.2 | $0.05 | Yes |
Accuracy Held Flat
92% across all three quantization levels. Identical. Not "within margin of error" — literally the same accuracy, the same precision per task type, the same recall, the same F1 scores.
For this constrained classification task, the model's reasoning doesn't degrade at lower precision. The task is pattern matching on a short text list, not nuanced generation. The model needs to read a list of DOM elements, match text patterns to a target concept, and pick one. That doesn't require the full representational fidelity of 16-bit floating point.
This is the headline. The quality fear is unfounded for this class of task.
Latency Tells the Real Story
The accuracy numbers are interesting. The latency numbers are where the operational impact lives.
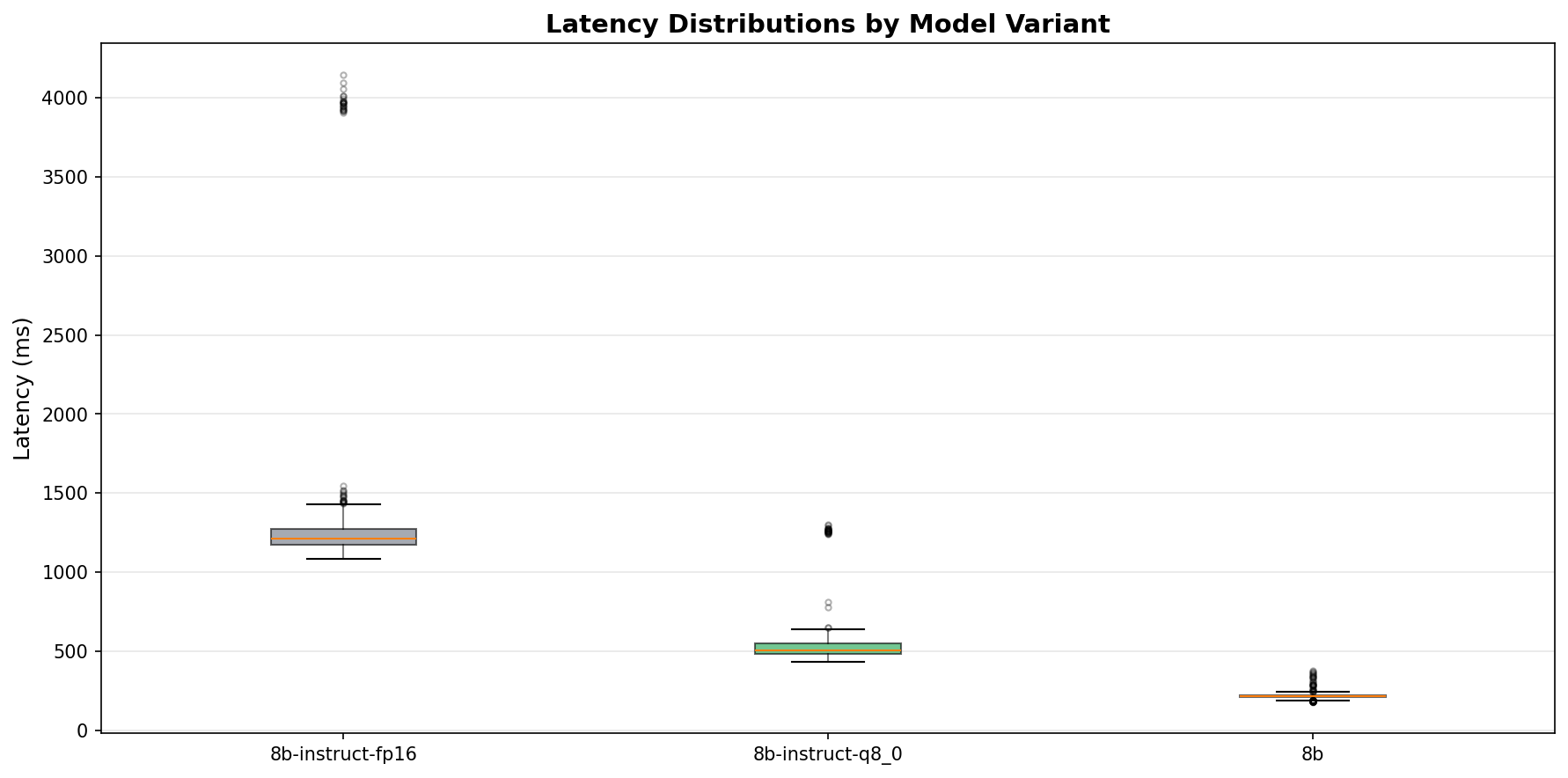
FP16 at 15.5 GB on an 8 GB VRAM card causes spilling to system RAM. The latency distribution is bimodal — most requests complete in about 1.2 seconds, but there's a long tail stretching past 4 seconds. That's VRAM thrashing. The model doesn't fit, so the GPU swaps pages back and forth with system memory. Every swap is a stall.
Q4_0 fits comfortably in VRAM at 5.0 GB. The p50/p95 spread is tight: 216ms to 254ms. No bimodal distribution. No tail. Predictable, consistent inference times.
In production, predictable latency matters more than fast latency. A p95 of 254ms means you can set reasonable timeouts, size your queues, and give users consistent response times. A p95 of 1,511ms with a bimodal distribution means you're guessing.
The Error Analysis Proves It's Not Quantization
All three variants achieve 100% recall — they never miss a correct element when one exists. Precision is ~93% on careers tasks and ~90% on contact tasks, consistently across all quantization levels.
The 8% error rate is entirely false picks: the model selects an element when the correct answer is NONE. It's overconfident about marginal matches. This error profile is identical across FP16, Q8_0, and Q4_0. Same mistakes, same cases, same confusion pattern.
That means the errors are a prompt/task design issue, not a quantization artifact. The model's decision boundary for "good enough match vs. no match" is the same at every precision level. Fixing this requires better prompt engineering or a confidence threshold — not more floating point bits.
Cost and Throughput at Scale
9.2 tokens per second vs. 1.5. That's 6x more concurrent users on the same hardware. At $0.05 per 1,000 queries vs. $0.30, you run 6x more verification queries for the same budget.
For a pipeline processing thousands of companies — which is what Blueprint does — that's the difference between feasible and prohibitive. At FP16 pricing, scaling to 10,000 companies costs $3,000 in inference alone. At Q4_0, it's $500. Same accuracy. Same error profile. The only thing that changed is the number on the invoice.
What This Means
The business case is straightforward: if you're serving a domain-specific LLM for structured classification tasks and you're paying FP16 prices, you're overpaying. The quality loss people fear is real for open-ended generation and complex multi-step reasoning. It's not real for constrained classification where the output space is bounded and the evaluation criteria are deterministic.
The architectural implication is more interesting. Quantization is the first cost lever, but you can't just pull it and hope. You need a way to measure the impact before you ship. A champion/challenger evaluation framework — run your golden test set against the quantized variant, compare metrics, promote the Pareto-optimal configuration — is how you pull that lever safely. You don't guess. You measure, compare, and promote. That's what this benchmark harness does, and it's the same pattern I described in making small LLMs production-safe: treat model outputs as untrusted until validated.
The benchmark harness is now part of the pipeline. Any time I swap models, change quantization, or modify prompts, the same 25 test cases run and the same metrics get compared. The cost of running it is trivial. The cost of not running it is shipping a regression you didn't measure.
Where This Goes Next
Two directions.
LoRA fine-tuning. The pipeline's own high-confidence verified outputs are training data waiting to happen. The hypothesis: a LoRA-adapted model at Q4_0 could push accuracy above 92% while maintaining the cost advantage. The 8% error rate is false picks on ambiguous cases — exactly the kind of decision boundary a domain-specific adapter should sharpen. The training data comes from the cascade's own confidence-gated outputs. The system generates its own supervised training set.
Specialized inference hardware. INT4 quantization is the first cost lever. The second is the hardware it runs on. GPUs are general-purpose compute — they're good at everything, optimal for nothing. ASICs designed specifically for transformer inference (Groq's LPU, Google's TPU) could compress that $0.05 per 1,000 queries by another order of magnitude. The companies that combine aggressive quantization with specialized hardware will have cost structures that make LLM-powered products viable at scales that are prohibitive today.
Quantization got us from $0.30 to $0.05. LoRA could push accuracy higher at the same cost. Purpose-built silicon could push cost lower at the same accuracy. Each lever compounds.
The full source for both the KYB pipeline and the benchmark harness is on GitHub: avatar296/blueprint.
Have questions about this topic?
We love talking tech. Reach out and let's discuss how this applies to your business.