Twelfth post in a series on building business process automation at scale. Infrastructure. Automation. Where automation fails. Statistical validation. Predictive models. When models disagree. A working system. Framework vs. architecture. MCP server. Making small LLMs safe. Quantization benchmark. This time: the full experiment — quantization, a smaller model, self-training data, and a fine-tuning failure that taught more than success would have.
The short version: I benchmarked 7 variants of Llama 3 on a real production verification pipeline — not a synthetic benchmark. Three quantization levels of the 8B model all hit 92% accuracy. A 3B challenger got close at 84% but left an 8% gap from a different class of error. I built a self-training pipeline that generates labeled data from the cascade's own high-confidence outputs — 542 examples, zero manual labeling. Then I fine-tuned a QLoRA adapter on the 3B model to close the gap. It scored 12% — worse than random. The model said NONE to everything. Catastrophic forgetting from overaggressive LoRA rank on a small model. The failure was more instructive than success would have been. Here's the data and the debugging story.
The Task
Blueprint's KYB (Know Your Business) verification engine discovers company career pages through a 4-layer agentic cascade. Layer 2 sends a list of DOM elements scraped from a company's website to a local Llama 3 model via Ollama and asks: which element most likely leads to the target page? The model responds with a number or NONE.
Structured input. Bounded output space. Deterministic evaluation criteria. A constrained classification task — and that distinction matters for interpreting everything that follows.
The model runs on a single Hetzner dedicated server with an NVIDIA RTX 4060 (8GB VRAM). No cloud GPU spend. Everything local, everything sovereign.
This post covers the full experiment: can we cut cost through quantization, shrink the model, generate our own training data, and fine-tune our way to higher accuracy? The answer to the first three is yes. The last one broke.
Phase 1: Quantization Is Free
The first question was simple: does reducing numerical precision degrade accuracy on this task?
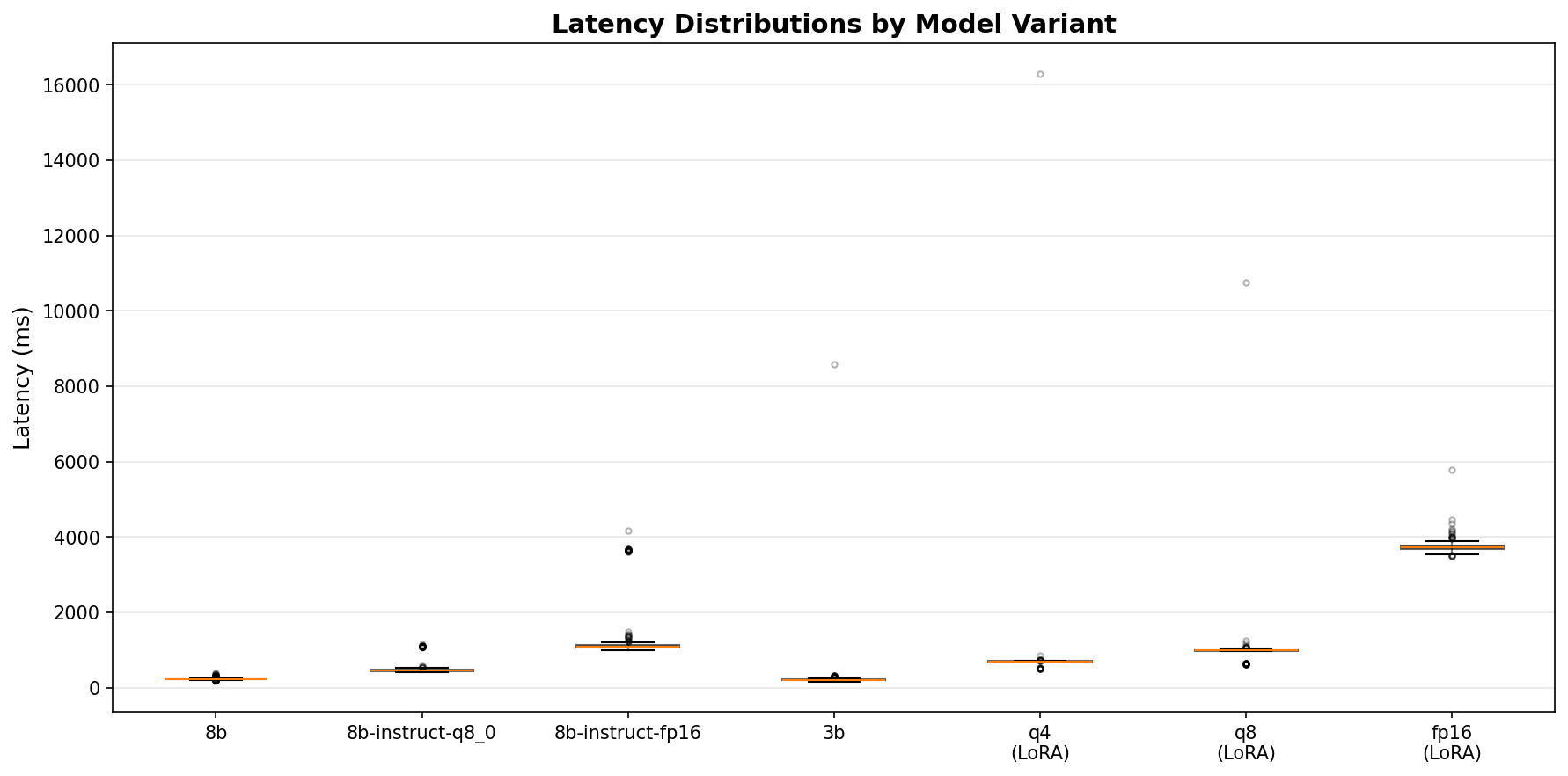
I built a benchmark harness that tests three quantization levels of Llama 3 8B against 25 golden test cases (15 careers, 10 contact) across 50 runs each. Same code path as production, just with instrumented timing and a fixed test set. The full deep-dive is here. The headline:
| Variant | Quant | Accuracy | P50 (ms) | P95 (ms) | Memory | Tok/s | Cost/1K |
|---|---|---|---|---|---|---|---|
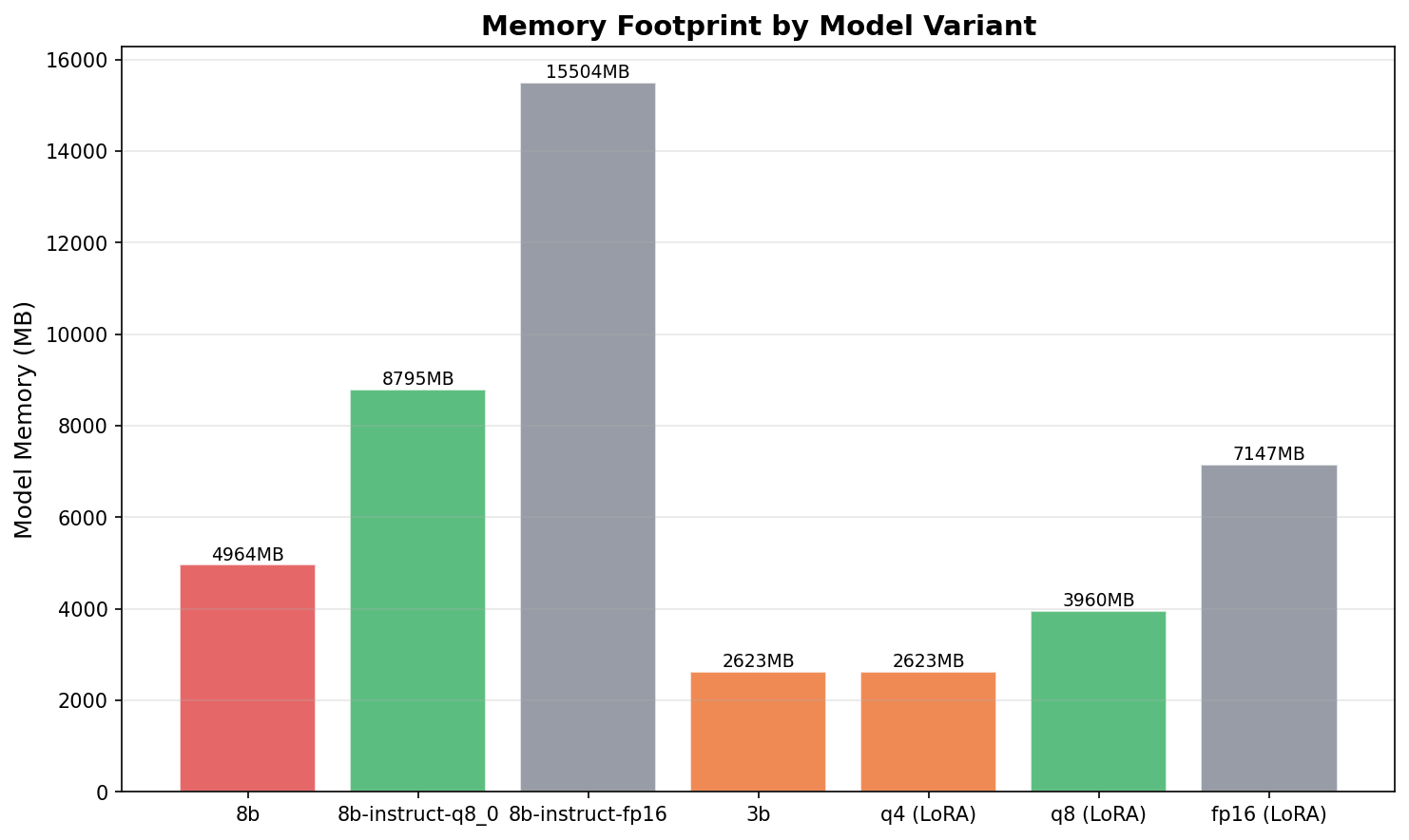
| Llama 3 8B | Q4_0 | 92.0% | 219 | 294 | 5.0 GB | 8.9 | $0.05 |
| Llama 3 8B | Q8_0 | 92.0% | 459 | 1,087 | 8.8 GB | 3.9 | $0.12 |
| Llama 3 8B | FP16 | 92.0% | 1,091 | 3,645 | 15.5 GB | 1.5 | $0.30 |
Identical accuracy across all three levels. Not "within margin of error" — the same precision, recall, and F1 scores per task type. The same confusion matrix. The same mistakes on the same cases.
Q4 is the Pareto champion: 5x faster, 3x less memory, 6x cheaper than FP16. The 8% error rate (false picks on ambiguous NONE cases) is identical across all three — it's a prompt/task design issue, not a precision issue. Quantization is a free lunch for this class of task.
But 92% isn't 100%. And the errors follow a pattern: the model picks an element when the correct answer is NONE. The 8B model's decision boundary for "good enough match vs. no match" is fuzzy. Could a different approach close the gap?
Phase 2: The 3B Challenger
If quantization doesn't degrade quality, what about a smaller model entirely? Llama 3.2 3B at Q4_K_M — less than half the parameters, half the VRAM.
The Numbers
| Metric | Llama 3 8B Q4 | Llama 3.2 3B Q4 |
|---|---|---|
| Accuracy | 92.0% | 84.0% |
| P50 latency | 219 ms | 197 ms |
| P95 latency | 294 ms | 289 ms |
| Memory | 5.0 GB | 2.6 GB |
| Tok/s | 8.9 | 8.4 |
| Cost/1K | $0.050 | $0.053 |
The 3B is 10% faster and uses half the VRAM. It also drops 8 percentage points on accuracy.
Where the 8% Gap Lives
The error profiles are different in a way that matters.
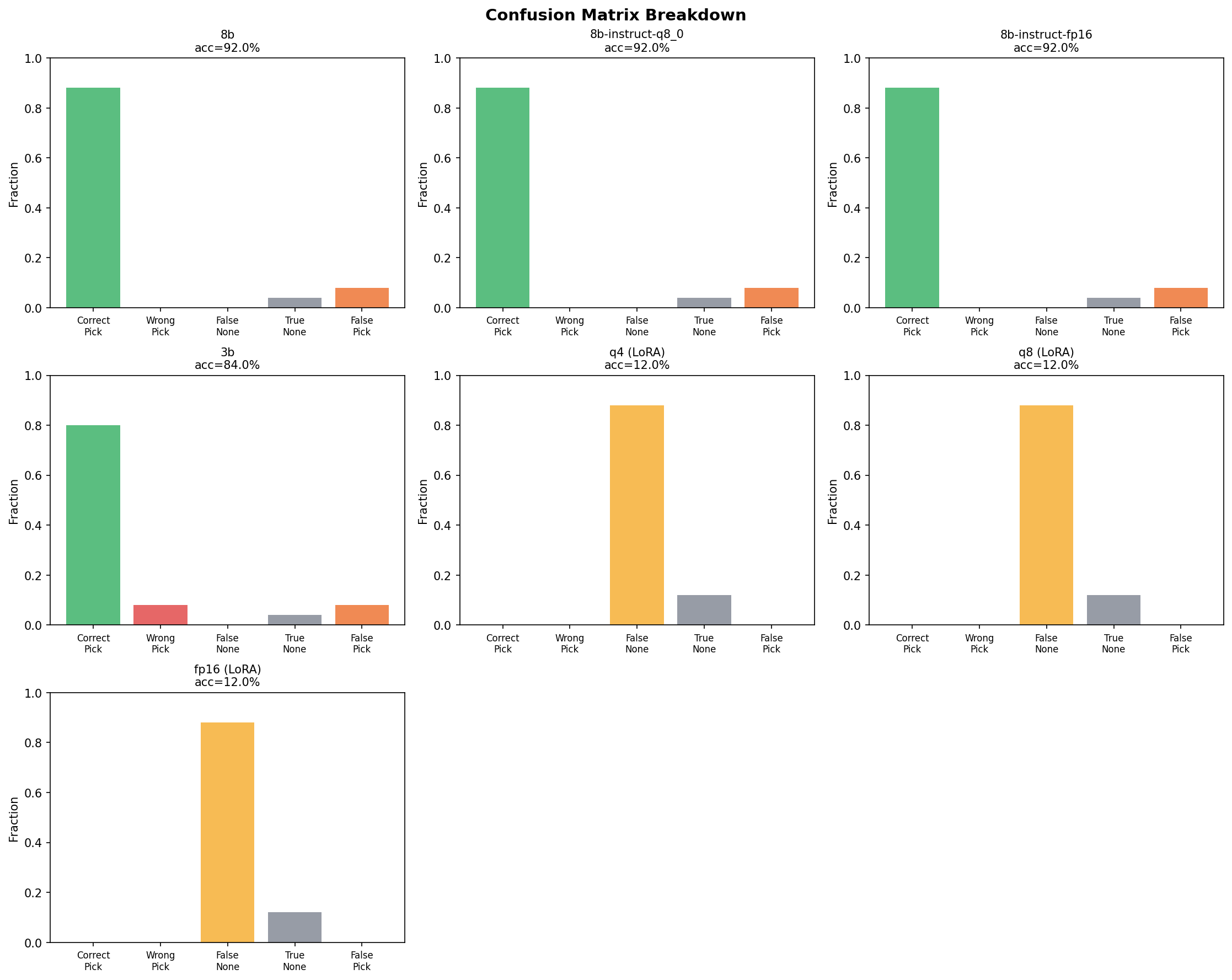
The 8B model's errors are exclusively false picks — it selects an element when the correct answer is NONE. It never picks the wrong element; when there's a correct answer, it finds it. 100% recall.
The 3B model has a different problem. It has false picks too (20), but it also makes wrong picks (20) — selecting the wrong element from the list entirely. It picks "About Us" when the answer is "Careers." It picks "Contact Sales" when the answer is "Contact Us." The smaller model lacks the capacity to distinguish between superficially similar DOM elements.
This is the "8% problem" from the title. The gap between 84% and 92% isn't just a NONE-boundary issue — it's a reasoning quality issue. The 3B model makes confident but incorrect selections that the 8B model never makes.
The Cost Paradox
Here's the counterintuitive result: the 3B model is not cheaper. $0.053 vs $0.050 per thousand queries. The latency advantage is marginal (197ms vs 219ms). The only dimension where the 3B wins is VRAM — 2.6 GB vs 5.0 GB. If you're running multiple models on the same GPU, that headroom matters. For a single-model deployment, the 8B Q4 dominates on every metric that matters.
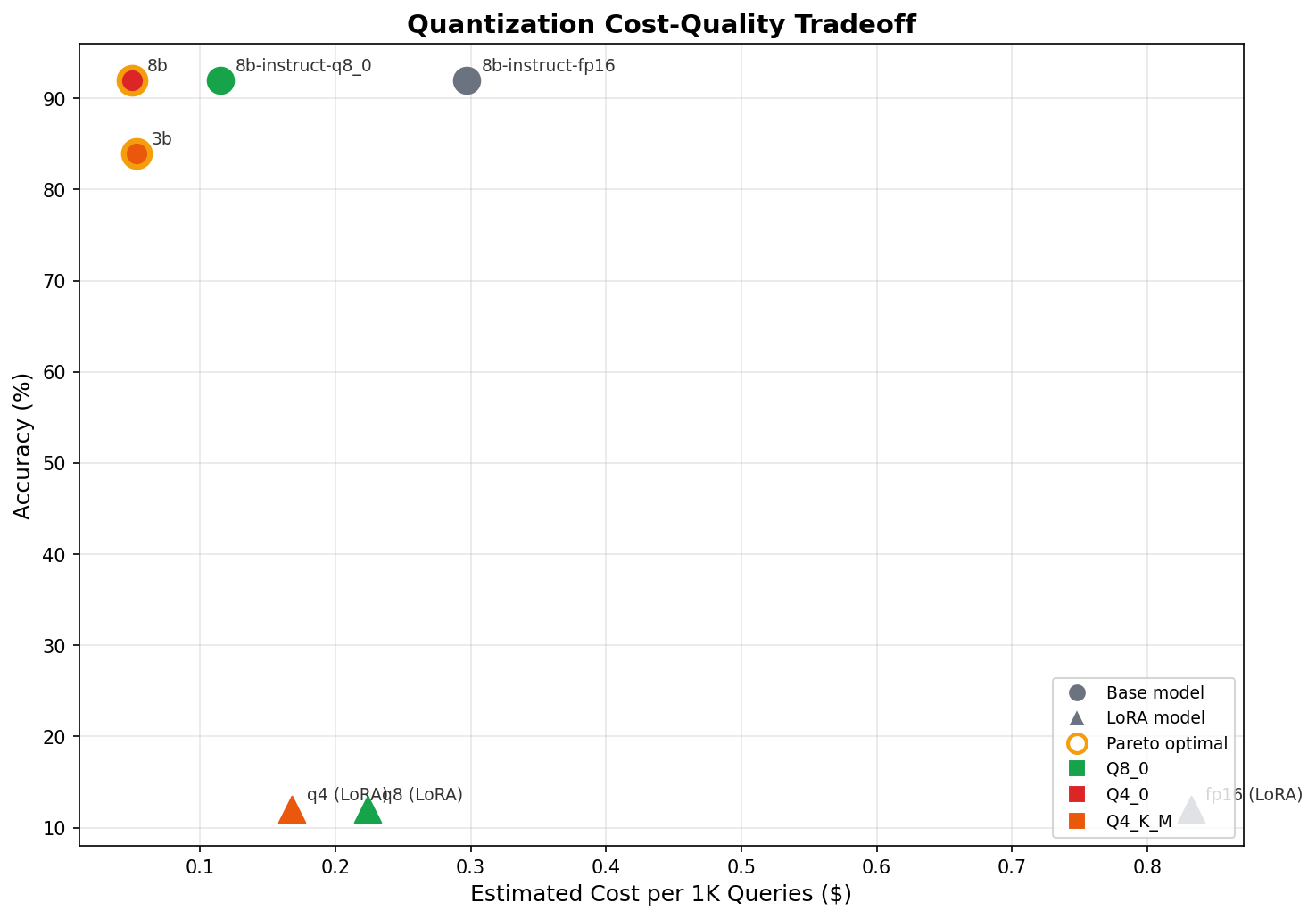
Both models sit on the Pareto frontier — the 8B optimizes for accuracy, the 3B optimizes for memory. But for this pipeline, accuracy is the binding constraint.
Phase 3: Building a Self-Training Pipeline
The 8% gap suggested fine-tuning. But where do you get training data for a domain-specific classification task where the inputs are scraped DOM elements from arbitrary company websites?
The answer: the cascade itself.
Confidence-Gated Training Data
The KYB verification cascade is 4 layers deep. Each layer produces signals that, taken together, tell you how confident you should be in the result:
- DOM scoring picks an element AND downstream ATS detection confirms a careers page exists → high-confidence correct pick. That (prompt, response) pair is a training example.
- All 4 layers fail to find a target page → high-confidence NONE. The company genuinely doesn't have a public careers page.
- The LLM says NONE, but the probe layer (Layer 4) finds a careers page anyway → the LLM was wrong. This is the most valuable training signal because it directly addresses the false-NONE error mode.
- The LLM picks an element, but ATS detection doesn't confirm → low confidence. Hold it out for edge case evaluation, not training.
The insight is architectural: the production pipeline generates its own labeled training data. The downstream verification layers provide the labels. No manual annotation required.
The Numbers
I ran 1,000 companies through the full cascade and applied confidence gating:
- 542 training examples from 446 high-confidence outputs
- 328 positive picks (322 from DOM scoring, 6 from LLM layer)
- 110 high-confidence NONEs
- 8 probe-corrected examples (LLM said pick, probe said NONE)
- 2x NONE oversampling to combat the false-pick bias → effective ratio of 328 picks to 220 NONEs
- 117 edge cases from low-confidence outputs, held out for evaluation
One critical design choice: the training data formatter uses the exact same prompt-building functions as the production inference path. build_llm_prompt() and prepare_elements() produce identical prompts whether the model is being trained or doing real inference. No prompt template mismatch between training and serving — a common failure mode in fine-tuning pipelines.
Phase 4: QLoRA Fine-Tuning
This is where the experiment went sideways.
The Setup
QLoRA on Llama 3.2 3B Instruct via Unsloth. The 8B model didn't fit for training on 8GB VRAM even in 4-bit — Unsloth's fused cross-entropy loss kernels need more memory than inference alone.
Training config:
- LoRA: rank=16, alpha=32, dropout=0.05
- Target modules: all linear layers — q, k, v, o projections plus gate, up, down MLP layers
- Training: 3 epochs, batch size 1, gradient accumulation 8 (effective batch 8)
- Optimizer: AdamW 8-bit, learning rate 2e-4, warmup 10%, weight decay 0.01
- Precision: bf16, 4-bit NF4 base model quantization
- Duration: 204 steps, 32 minutes on the RTX 4060
The training loss curve looked perfect. Smooth descent from 2.0 to 0.57 over 204 steps. No spikes, no plateaus, no signs of instability.
I exported the merged model to GGUF at three quantization levels (FP16, Q8, Q4), registered all three with Ollama, and ran the benchmark.
The Results
| Variant | Quant | LoRA | Accuracy | P50 (ms) | Memory | Cost/1K |
|---|---|---|---|---|---|---|
| Llama 3 8B | Q4_0 | — | 92.0% | 219 | 5.0 GB | $0.050 |
| Llama 3 8B | Q8_0 | — | 92.0% | 459 | 8.8 GB | $0.115 |
| Llama 3 8B | FP16 | — | 92.0% | 1,091 | 15.5 GB | $0.297 |
| Llama 3.2 3B | Q4_K_M | — | 84.0% | 197 | 2.6 GB | $0.053 |
| Llama 3.2 3B | Q4_K_M | LoRA | 12.0% | 697 | 2.6 GB | $0.168 |
| Llama 3.2 3B | Q8_0 | LoRA | 12.0% | 982 | 4.0 GB | $0.224 |
| Llama 3.2 3B | FP16 | LoRA | 12.0% | 3,717 | 7.1 GB | $0.832 |
12% accuracy. Across all three quantization levels. The LoRA adapter didn't just fail to close the 8% gap — it destroyed the model's ability to do the task at all.
The confusion matrix tells the story instantly: 100% NONE rate. The fine-tuned model says NONE to every single query. 220 false NONEs (cases where there was a correct element to pick), 30 true NONEs (cases where NONE was actually right). The only "correct" answers are the NONE cases it got right by always saying NONE.
Zero correct picks. Zero wrong picks. Zero precision. Zero recall. The model learned one thing: say NONE.
The Debugging Journey
The first instinct was wrong. And so was the second.
Hypothesis 1: Chat template mismatch. The GGUF export uses a custom Modelfile with the Llama 3.2 Instruct chat template — start/end header IDs, role formatting, stop tokens. If the template was wrong, the model would see garbled input and produce garbage. I verified every token: <|start_header_id|>, <|end_header_id|>, <|eot_id|>, role tags. All correct. The template matched the base model's exactly. Not the cause.
Hypothesis 2: Merge corruption. Unsloth's save_pretrained_gguf() merges LoRA weights into the base model before GGUF conversion. If the merge produced NaN weights or numerical instability, all outputs would be garbage. But the model wasn't producing garbage — it was producing "NONE" in the correct format, consistently, coherently. It understood the task format. It just always chose the same answer. Corrupted weights produce gibberish, not consistent single-token responses. Not corruption.
Hypothesis 3: Catastrophic forgetting. I tested the model on basic questions outside the training domain. "What is 2+2?" The response: EVEN. Reply only (e.g., , ) or ONLY... — fragments of the training prompt format, not an answer. The model wasn't just broken on the KYB task. It had forgotten how to be a language model.
This was the root cause. Rank=16 LoRA modifying all seven linear layer types in every transformer block is too aggressive for a 3B parameter model. The ratio of modified parameters to total parameters was too high. The adapter didn't learn to supplement the base model's knowledge — it overwrote it.
The training loss was misleading. The smooth descent from 2.0 to 0.57 showed the model memorizing the format tokens of the training examples — learning to emit the right special tokens and response structure — not generalizing from the training distribution to unseen inputs. With only 542 examples and 3 epochs, there wasn't enough data diversity to prevent the model from collapsing to the most "safe" response: NONE is never a wrong pick, it's only a missed pick. The model learned that saying nothing is better than saying something wrong.
Why the Failure Is Instructive
This failure clarified three things that success would have obscured:
Loss curves lie. A smooth loss descent is necessary but not sufficient. The curve showed memorization of format tokens, not generalization to the task. Always benchmark the merged model on held-out data before declaring victory. If I'd only looked at the training metrics, I'd have shipped a model that says NONE to everything.
Small models need gentle fine-tuning. Rank=16 on a 3B model is too aggressive. The parameter budget of LoRA (rank x 2 x hidden_dim x num_layers x num_modules) as a fraction of total model parameters matters. For a 3B model, rank=4-8 with a lower learning rate (5e-5 instead of 2e-4) and fewer target modules would preserve more of the base model's capability. The same config that works on a 7B or 13B model can destroy a 3B model.
The cascade architecture is more robust than model improvement. The 4-layer verification cascade catches errors at layers above the model. The defensive AI patterns treat every model output as untrusted until verified. Trying to make the model "smarter" via LoRA is fragile. Making the system around the model smarter is durable. The architecture is the product, not the model.
What We Learned
-
Quantization is free for classification tasks. Q4_0 matches FP16 exactly on this element-picking task. Same accuracy, same error profile, 6x cheaper. Don't pay for precision you don't need.
-
Loss curves lie. A smooth descent from 2.0 to 0.57 looked like successful training. The model had memorized the format, not the task. Always benchmark the merged model on held-out data before declaring victory.
-
Small models need gentle fine-tuning. Rank=16 on a 3B model is too aggressive. The ratio of modified parameters to total parameters matters. For small models, use rank=4-8, lower learning rate (5e-5), and fewer target modules.
-
Self-training pipelines are the real asset. The 542-example dataset generated from production cascade outputs is reusable. When we fine-tune with better hyperparameters — or on a larger model with more VRAM — the data infrastructure is already built. Zero manual labeling.
-
The Pareto frontier is clear without fine-tuning. Llama 3 8B at Q4 delivers 92% accuracy at 219ms for $0.05 per thousand queries on a consumer GPU. The 8% gap to perfect isn't worth chasing with the current hardware constraints — the cascade's downstream layers catch the errors the model misses.
Where This Goes Next
Two directions.
Better training strategy. The same 542 examples with gentler hyperparameters — rank=4, learning rate 5e-5, target only attention layers, single epoch. Or DPO (Direct Preference Optimization) instead of SFT, which teaches the model to prefer correct picks over NONE without overwriting its base capabilities. DPO is better suited for tasks where the model already mostly works and you're sharpening a decision boundary.
Cascade improvement over model improvement. Instead of making the LLM smarter, make the layers around it smarter. Better confidence thresholds for when to escalate. Better probe strategies for catching false NONEs. Better downstream verification for catching false picks. The architecture is designed to compensate for model limitations — investing in the compensation layers may be more durable than investing in the model itself.
The quantization benchmark proved we're not leaving performance on the table. The self-training pipeline proved we can generate our own training data at zero marginal cost. The LoRA failure proved that the next improvement isn't a model problem — it's a systems problem. Each experiment narrowed the search space for where the next 8% of accuracy actually lives.
The full source for the KYB pipeline, benchmark harness, and LoRA training code is on GitHub: avatar296/blueprint.
Have questions about this topic?
We love talking tech. Reach out and let's discuss how this applies to your business.